华为昇腾(Ascend)开发考试原题目解析 (2024)(题库二) —— HCIP-AI-Ascend Developer - 第一部分
A. TBE-TIKB. TBE-DSLC. TBE-DDLD. TVME. MindSpore算子模板正确答案解析:基于 Python 的领域特定语言,语法简洁、抽象度高,封装了大量常用操作,开发者无需关心底层硬件细节,非常适合初学者快速开发和调试。:底层算子开发方式,需要手动控制内存分配和指令调度,更适合对性能有极致要求的高级开发者。TBE-DDL:硬件中间层接口开发方式,主要用于算子定义描述
华为昇腾(Ascend)开发考试原题目解析 (2024)(题库二) —— HCIP-AI-Ascend Developer - 第一部分
E选项为补充选择,不在原题库中
单选题
1. 以下哪个选项不属于 LeNet-5 的网络结构?
A. 全连接层
B. 嵌入层
C. 池化层
D. 卷积层
E. 自注意力层
正确答案:B. 嵌入层
解析:
LeNet-5 是由 Yann LeCun 等人提出的一种经典卷积神经网络(CNN)架构,主要用于手写数字识别。它的网络结构包括:
- 卷积层(Convolutional Layer):用于提取局部特征。
- 池化层(Pooling/Subsampling Layer):用于降维和提高特征鲁棒性。
- 全连接层(Fully Connected Layer):将提取的特征映射到输出空间。
- 激活函数(如 sigmoid 或 tanh):进行非线性变换。
不包含的层:
- 嵌入层(Embedding Layer):主要用于将离散的分类变量(如词汇表中的单词)映射到低维连续空间,常用于自然语言处理(NLP)任务,而 LeNet-5 并不处理这类输入。
- 自注意力层(Self-Attention Layer):是 Transformer 网络中的核心模块,用于建模长距离依赖,在 LeNet-5 中完全没有涉及。
2. 昇腾310芯片可以拓展外设时,其PCIe的工作模式是哪种模式?
A. RC模式
B. EC模式
C. EP模式
D. RP模式
E. NT模式
正确答案:A. RC模式
解析:
昇腾310(Ascend 310)是华为开发的AI推理芯片,常用于边缘计算场景。在进行外设拓展时,芯片通过 PCIe 总线与其他设备通信。
- RC模式(Root Complex):根复杂体模式,表示设备处于主控端角色,能够主动发起访问请求。昇腾310 在拓展外设时,以主控端的身份存在,因此其 PCIe 工作模式为 RC 模式。
- EP模式(End Point):终端设备模式,表示设备为从属设备(如网卡、显卡等),响应主控的请求。
- NT模式(Non-Transparent Bridge):非透明桥接模式,常用于多处理器系统之间的数据通信。
- EC模式 / RP模式:在标准 PCIe 架构中不是常见或标准定义的模式。
3. 以下哪个产品可以组成 Atlas 分布式训练平台?
A. Atlas 300T
B. Atlas 200
C. Atlas 800
D. Atlas 500
E. Atlas 900
正确答案:C. Atlas 800
解析:
Atlas 是华为推出的一系列基于昇腾 AI 处理器的人工智能计算平台。
- Atlas 200 和 Atlas 500 主要面向边缘计算和推理场景。
- Atlas 300T 主要用于推理加速。
- Atlas 800 是具备大算力的AI训练服务器,可作为 Atlas 分布式训练平台的基础单元。
- Atlas 900 是华为的旗舰级 AI 训练集群,通常由多台 Atlas 800 组成,是完整的大规模分布式训练平台集群解决方案。
虽然 Atlas 900 是分布式训练平台,但题目问的是哪个产品可以组成该平台,Atlas 800 是构成集群的基础节点,因此是正确答案。
4. 以下哪种自定义算子开发方式更适合入门开发者?
A. TBE-TIK
B. TBE-DSL
C. TBE-DDL
D. TVM
E. MindSpore算子模板
正确答案:B. TBE-DSL
解析:
昇腾AI芯片支持多种自定义算子开发方式:
- TBE-DSL(Domain Specific Language):基于 Python 的领域特定语言,语法简洁、抽象度高,封装了大量常用操作,开发者无需关心底层硬件细节,非常适合初学者快速开发和调试。
- TBE-TIK(Tensor Instruction Kernel):底层算子开发方式,需要手动控制内存分配和指令调度,更适合对性能有极致要求的高级开发者。
- TBE-DDL:硬件中间层接口开发方式,主要用于算子定义描述。
- TVM:一个开源的深度学习编译器栈,跨平台但学习曲线陡峭。
- MindSpore算子模板:虽然也适合新手,但主要用于图级融合与高层封装,不如 TBE-DSL 灵活。
对于入门开发者,TBE-DSL 是最佳选择。
5. John 在查看 CANN 的功能介绍时发现有 TBE 子系统,其中有一个代码生成模块,那么这个模块的作用是什么?
A. 使用内置模板,快速生成自定义算子开发的代码
B. 生成类字节码的与硬件无关的代码,可被网络模型直接加载调用
C. 生成类 C 代码的临时文件,可以通过编译器生成算子的实现文件
D. 生成机器码,是华为自主研发的用于编译算子的编译器
E. 生成中间 IR 表达式,供 CCE 编译器优化使用
正确答案:C. 生成类 C 代码的临时文件,可以通过编译器生成算子的实现文件
解析:
TBE(Tensor Boost Engine)是华为昇腾 CANN 软件栈中用于自定义算子开发的重要子系统。其代码生成模块的主要作用是将开发者用 TBE-DSL 或 TBE-TIK 编写的算子逻辑,转化为 C-like 的中间代码文件(如 .cce)。这些文件随后被 CCE(Compute Compiler Engine)编译器进一步编译,最终生成可在昇腾处理器上执行的二进制指令。因此,该模块是连接高层算子定义与底层硬件执行的桥梁。
6. John 购买了 Atlas 200DK,在查看官网文档时发现 CANN 提供了很多功能模块,现在他想使用一款 IDE 来快速开发应用,他应该选择哪一个?
A. MindStudio
B. MindSpore
C. VisualStudio
D. PyCharm
E. AscendLab IDE
正确答案:A. MindStudio
解析:
- MindStudio:是华为官方推出的昇腾平台专用集成开发环境(IDE),它集成了 CANN 的全套工具链,支持模型转换、推理部署、性能分析、自定义算子开发等功能,是为 Atlas 系列产品(如 Atlas 200DK)量身打造的开发工具。
- MindSpore:是华为的深度学习框架,而非 IDE。
- VisualStudio 和 PyCharm:是通用的 IDE,但无法直接集成 CANN 工具链,需要手动配置,不适合快速开发。
- AscendLab IDE:并非官方主推的独立 IDE 产品。
因此,MindStudio 是最合适的选择。
7. 以下哪个选项是华为公司推出的 AI 计算框架?
A. TensorFlow
B. MindSpore
C. PyTorch
D. 略
E. AscendCL
正确答案:B. MindSpore
解析:
- MindSpore:是华为自主研发的全场景 AI 框架,对标 TensorFlow 和 PyTorch,支持端、边、云协同部署,并与华为昇腾 AI 处理器深度适配。
- TensorFlow:由 Google 推出。
- PyTorch:由 Facebook (Meta) 开发。
- AscendCL:是华为昇腾芯片的底层算子编程接口(API)库,用于推理应用的部署,属于 CANN 的一部分,而不是一个完整的 AI 计算框架。
8. 某厂商希望开发一款应用,可以实现实时人像抠图然后完成背景替换。现在应用使用 AscendCL 开发,硬件使用了 Atlas 200DK,图像数据预处理部分使用了 OpenCV 编写。在实际运行时发现效果很不理想,帧数很低,可以采用以下哪些方式提升效果?
A. 数据预处理采用 AscendCL 提供的 CV2 接口
B. 更换推理准确性更高的模型
C. 使用 DVPP 模块进行推理
D. 降低输入和输出视频的分辨率
E. 使用 DVPP 模块进行图像预处理加速
正确答案:D. 降低输入和输出视频的分辨率
解析:
该场景的性能瓶颈主要在于数据处理量和计算效率。
- D. 降低输入和输出视频的分辨率:分辨率越高,需要处理的像素量就越大,直接导致模型推理和图像处理的耗时增加。降低分辨率是提升帧率最直接有效的方法之一。
- E. 使用 DVPP 模块进行图像预处理加速:OpenCV 主要在 CPU 上运行,而 DVPP(Digital Video Pre-Processing)是昇腾芯片内置的硬件加速模块,专门用于视频解码、缩放、裁剪等预处理任务。将预处理从 CPU (OpenCV) 迁移到 NPU 上的 DVPP,可以大幅减少数据在 Host 和 Device 之间的拷贝,并利用硬件加速,显著提升性能。虽然选项 E 也是正确的优化方式,但在单选题中,降低分辨率(D)是更普适且直接的性能提升手段。
- A: AscendCL 不提供 CV2 接口。
- B: 更换更精确的模型通常会增加计算量,可能导致帧率更低。
- C: DVPP 用于图像预处理,不负责模型推理。
9. AscendCL 功能包含算子能力开放,以下哪个选项描述是正确的?
A. AscendCL 可以用来做算子映射
B. AscendCL 可以用来加载算子
C. AscendCL 可以用来进行算子调优
D. AscendCL 可以用来开发自定义算子
E. AscendCL 可以调用已编译算子的推理函数
正确答案:B. AscendCL 可以用来加载算子
解析:
AscendCL(Ascend Computing Language)是华为昇腾 AI 处理器提供的基础推理加速接口库。它的核心职责是在部署和运行阶段管理资源和任务。
- B 和 E:AscendCL 提供了 API(如
aclopExecuteV2)来加载和执行已经编译好的单个算子(.om文件),这是其核心功能之一。选项 E 是对 B 的更具体描述。 - A:算子映射是由 CANN 编译器在模型转换阶段完成的。
- C:算子调优通常由 MindStudio 或其他性能分析工具完成。
- D:自定义算子开发应使用 TBE-DSL/TIK。
AscendCL 的主要作用是调用而非开发或优化算子。
10. 有一台 X86 架构的服务器,装有一张 Atlas 300I 推理卡,在开发推理应用时需要考虑 Host 和 Device,针对当前服务器 Host 和 Device 分别是指什么?
A. Host 是推理卡,Device 是指推理卡中的 AI Core
B. Device 是指装有推理卡的服务器,Host 是指推理卡
C. Host 是装有推理卡的服务器,Device 是指推理卡
D. Host 和 Device 都是指推理卡
E. Host 是 CPU 系统,Device 是 Ascend AI 芯片加速器
正确答案:C. Host 是装有推理卡的服务器,Device 是指推理卡
解析:
在异构计算架构中,Host 和 Device 是标准概念。
- Host(主机):指的是控制端,通常是 CPU 所在的系统。它负责运行主程序逻辑、数据准备、任务分发等。在此场景中,X86 架构的服务器就是 Host。
- Device(设备):指的是加速器端,负责执行计算密集型任务。在此场景中,安装在服务器上的 Atlas 300I 推理卡就是 Device。
- 选项 E “Host 是 CPU 系统,Device 是 Ascend AI 芯片加速器” 在概念上也是正确的,它从系统组件的角度描述,与选项 C 的含义一致。
11. 为了让模型在昇腾 AI 处理器上运行得更高效,华为推出了五维数据格式。在使用 ATC 进行模型转换时,可以通过设置参数来适配这种五维数据格式。请问这个参数的名称是什么?
A. is_input_adjust_hw_layout 和 is_output_adjust_hw_layout
B. is_adjust_five_dimension
C. is_adiust_efficient
D. is_input_five_dimension 和 is_output_five_dimension
E. enable_5d_format_adaptation
正确答案:A. is_input_adjust_hw_layout 和 is_output_adjust_hw_layout
解析:
昇腾处理器为了提升数据访存和计算效率,内部采用了一种特殊的五维(5D)Tensor 格式(如 NDC1HWC0)。为了让标准的四维(4D)格式(如 NCHW)模型能够高效运行,模型转换工具 ATC 提供了参数来自动进行数据布局的适配。
--is_input_adjust_hw_layout=true:该参数用于在模型转换时,自动调整模型输入的数据格式以适配硬件布局。--is_output_adjust_hw_layout=true:该参数用于调整模型输出的数据格式以匹配硬件最优布局。
其他选项均为不存在或不正确的参数名称。
12. 需要在训练/验证过程中执行特定的任务,可使用哪一个 MindSpore 模块?
A. mindspore.ops
B. mindspore.train.callback
C. mindspore.mindrecord
D. mindspore.nn.metrics
E. mindspore.train.monitor
正确答案:B. mindspore.train.callback
解析:
在 MindSpore 中,回调函数(Callback)机制用于在训练过程的特定阶段(如 epoch 开始/结束、step 开始/结束)执行预定义的操作。
mindspore.train.callback:这个模块包含了所有内置的回调类,如ModelCheckpoint(保存模型)、LossMonitor(打印损失)、TimeMonitor(记录时间) 等。开发者可以通过自定义或使用内置 Callback 来实现训练过程的监控、模型保存、学习率调整等功能。mindspore.ops:定义了基础的算子操作。mindspore.mindrecord:是 MindSpore 的专属数据格式。mindspore.nn.metrics:用于定义评估指标(如准确率)。mindspore.train.monitor:不是一个标准模块,而是某些 Callback 的功能体现,如LossMonitor。
13. Mary 想要进行回归任务,请问她可以使用哪个损失函数?
A. mindspore.nn.MSELoss
B. mindspore.nn.SampledSoftmaxLoss
C. mindspore.nn.BCELoss
D. mindspore.nn.SoftmaxCrossEntropyWithLogits
E. mindspore.nn.SmoothL1Loss
正确答案:A. mindspore.nn.MSELoss
解析:
回归任务的目标是预测一个连续值。
- A.
mindspore.nn.MSELoss(均方误差):计算预测值与真实值之差的平方的均值,是回归任务最常用的损失函数。 - E.
mindspore.nn.SmoothL1Loss(平滑L1损失):也用于回归任务。它结合了 L1 损失和 L2 损失的优点,在误差较小时表现像 MSELoss,在误差较大时表现像 MAELoss,对异常值不那么敏感,鲁棒性更强。 - B, C, D:均为分类任务的损失函数。
SampledSoftmaxLoss用于大词汇表多分类,BCELoss用于二分类,SoftmaxCrossEntropyWithLogits用于多分类。
对于标准的回归任务,MSELoss 是首选。如果数据中存在较多异常值,SmoothL1Loss 也是一个很好的选择。
14. 以下原函数图像对应的激活函数是哪个选项?
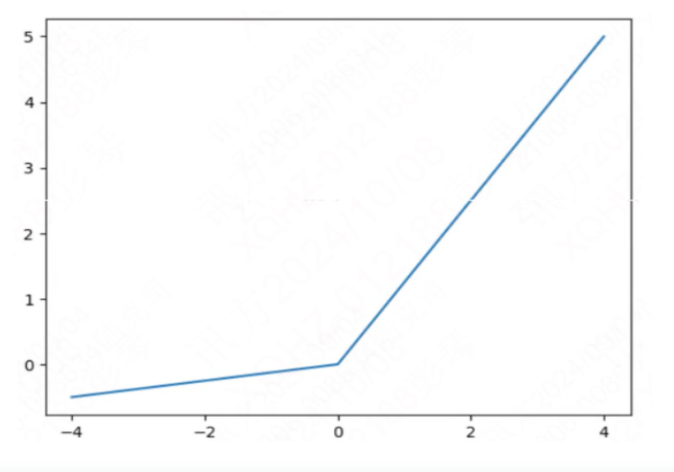
A. Tanh 函数
B. LeakyReLU 函数
C. ReLU 函数
D. Sigmoid 函数
正确答案:B. LeakyReLU 函数
解析:
- ReLU 函数:在正半轴为线性函数(f(x)=xf(x) = xf(x)=x),在负半轴为零(f(x)=0f(x) = 0f(x)=0)。其图像在 x<0 时是一条水平线。
- LeakyReLU 函数:是 ReLU 的改进版。它在正半轴与 ReLU 相同,但在负半轴有一个很小的正斜率 α\alphaα(f(x)=αxf(x) = \alpha xf(x)=αx),而不是完全为零。这解决了 ReLU 中神经元可能“死亡”的问题。其公式为:f(x)={xif x>0αxif x≤0f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \le 0 \end{cases}f(x)={xαxif x>0if x≤0。图像特征是原点处的折线,且在负半轴有向下的微小倾斜。题干描述的图像特征完全符合 LeakyReLU。
- Tanh 函数 和 Sigmoid 函数:均为 S 型曲线,取值范围分别在 (-1, 1) 和 (0, 1) 之间,与题图的线性特征不符。
15. 以下哪种自定义算子开发方式更适合入门开发者?
A. TBE-DSL
B. TBE-DDL
C. TBE-TIK
D. TVM
E. MindSpore算子模板引擎
正确答案:A. TBE-DSL
解析:
此题与第 4 题核心内容一致。对于入门开发者,TBE-DSL 是最适合的方式,因为它提供了高级的 Python API,屏蔽了底层硬件细节,使得开发者可以快速实现和验证算子逻辑。TBE-TIK 则需要手写汇编指令,难度较高;其他选项则用于不同目的或学习曲线更陡峭。
16. John 是一名 AI 工程师,平时喜欢使用 TensorFlow 训练模型,现在想要通过 AscendCL 把训练好的模型部署到搭载了 Atlas 300I 推理卡的服务器上,以下哪个选项是他无需关心的?
A. CANN 中是否已经适配了 TensorFlow 所训练模型中的所有算子
B. Atlas 300I 推理卡的固件和驱动升级方法
C. TensorFlow 训练模型时使用的硬件设备
D. CANN 中提供的 DVPP 子系统是否可以用于数据预处理
E. ATC 是否能兼容 TensorFlow 模型的算子结构
正确答案:B. Atlas 300I 推理卡的固件和驱动升级方法
解析:
作为一名应用/算法工程师,其主要职责是模型的开发、转换和部署。
- 需要关心:算子兼容性(A 和 E)、数据预处理方案(D)、以及训练和推理硬件差异可能带来的精度问题(C),这些都直接影响部署的成败和性能。
- 无需关心:固件和驱动的升级通常由运维人员或系统管理员负责。开发者只需要确保所使用的驱动和固件版本满足 CANN 软件栈的要求即可,无需关心具体的升级操作和方法。
17. 昇腾 AI 芯片在进行 AI 相关计算的时候运算效率非常高,其中核心原因是什么?
A. 昇腾 AI 芯片采用了 HBM 2.0 颗粒
B. 昇腾 AI 芯片具备独立的 TS CPU
C. 昇腾 AI 芯片采用了 7nm 工艺
D. 昇腾 AI 芯片的 CUBE 单元可以高效进行矩阵运算
E. 昇腾芯片支持原生张量化指令与并行调度架构
正确答案:D. 昇腾 AI 芯片的 CUBE 单元可以高效进行矩阵运算
解析:
AI 计算的核心是大量的矩阵和张量运算。昇腾 AI 芯片高性能的根本原因在于其专门的硬件设计。
- D. CUBE 单元:昇腾芯片内置了 AI Core,其核心是强大的 3D CUBE 计算单元。这个单元专门用于加速矩阵乘法运算,能够以极高的并行度执行,这正是神经网络(如 CNN、Transformer)中最主要的计算负载。
- A, C:高带宽内存(HBM)和先进的制造工艺(7nm)是性能的重要保障,但它们是通用的性能提升因素,不是 AI 计算效率高的“核心原因”。
- B:TS CPU(Task-Scheduler CPU)主要负责控制和调度,而非执行核心计算。
- E:原生张量指令和并行架构是对 CUBE 单元工作方式的描述和补充,但 CUBE 单元本身是实现高效矩阵运算的物理基础。
18. 构建神经网络时,以下哪个方法不可以减少模型参数量?
A. 参数量化
B. 模型重训练
C. 网络剪枝
D. 知识蒸馏
正确答案:B. 模型重训练
解析:
减少模型参数量是为了实现模型压缩,降低存储和计算开销。
- A. 参数量化:将高精度参数(如 FP32)用低精度参数(如 INT8)表示,可以大幅减小模型体积,但不改变参数的“数量”。
- C. 网络剪枝:移除网络中冗余的权重或神经元,直接减少了参数的数量。
- D. 知识蒸馏:用一个参数量更少的小模型(学生模型)去学习一个大模型(教师模型)的行为,从而得到一个性能接近但参数量更少的模型。
- B. 模型重训练:指在不改变模型结构的前提下,用新的数据或超参数重新训练模型。这个过程只更新参数的“值”,而不改变参数的“数量”,因此不能减少模型参数量。
19. 在使用 ATC 工具进行模型转换时可能会遇到各种问题,可以通过哪些方式来解决问题?
A. 查看转换日志
B. 到昇腾论坛发帖求助
C. 其余三种方式都可以
D. 查阅官方文档
正确答案:C. 其余三种方式都可以
解析:
解决 ATC 模型转换问题是一个综合性的过程,需要利用所有可用的资源。
- 查看转换日志:日志是排查问题的第一手资料,它会明确指出错误发生的位置和原因,例如算子不支持、维度不匹配等。
- 查阅官方文档:华为昇腾的官方文档详细说明了 ATC 工具的使用方法、参数含义以及常见问题(FAQ)的解决方案。
- 到昇腾论坛发帖求助:如果自己无法解决,可以在昇腾官方社区发帖,向华为的技术专家和其他开发者求助,社区中也沉淀了大量已解决的问题。
因此,这三种方式都是有效且互为补充的解决途径。
20. 以下哪个选项是 MindSpore 内置的回调函数?
A. AccuracyMonitor
B. SummaryCollector
C. SaveBest
D. LossRuducer
正确答案:B. SummaryCollector
解析:
MindSpore 在 mindspore.train.callback 模块中提供了一系列内置的回调函数。
SummaryCollector:是官方提供的内置回调函数,用于在训练过程中收集标量、图像、计算图等数据,并将其保存为可供 MindSpore Insight 或 TensorBoard 可视化的文件。- A. AccuracyMonitor:MindSpore 中没有此名称的内置回调。准确率通常通过
Model.eval和mindspore.nn.Metric类来监控。 - C. SaveBest:这个功能由
ModelCheckpoint回调函数实现,通过设置save_best_ckpt=True参数来保存最优模型。 - D. LossRuducer:拼写错误,且不存在该回调。监控损失值通常使用
LossMonitor。
21. 以下哪个选项是 MindSpore 的应用领域?
A. 量子加密算法
B. 5G 信号解析
C. 可控核聚变环境模拟
D. 高性能计算
正确答案:D. 高性能计算
解析:
MindSpore 是一个为 AI 计算设计的深度学习框架。大规模的 AI 模型训练本身就是一种典型的高性能计算(HPC)任务。MindSpore 通过自动并行、计算图下沉、与昇腾硬件协同优化等技术,能够充分利用计算资源,高效地执行大规模分布式训练,这使其在高性能计算领域具有显著优势。而其他选项,如量子加密、5G 信号处理、物理模拟等,虽然可能借助 AI,但并非 MindSpore 的核心或主要应用领域。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)