2024-2025华为ICT大赛中国区 实践赛昇腾AI赛道(高教组)全国总决赛 理论部分真题+解析
本文为2024-2025华为ICT大赛 中国区 全国总决赛 实践赛 昇腾AI赛道 高教组 理论部分考试真题以及对应详细解析,涵盖昇腾AI全栈系统模块6题、模型训练与调优模块8题、模型推理与应用模块6题。
Part 1 昇腾AI全栈系统模块(共6题):
1、MindSpore作为一个高效且灵活的深度学习框架,特别针对昇腾处理器进行了优化,提供了包括MindSpore Transformers在内的多种套件,以简化大模型的开发和部署流程。这些套件不仅能够提升开发效率,还能确保模型在昇腾处理器上的高效运行。以下关于MindSpore及其套件的描述错误的是哪一项?(单选题)
A. MindSpore Transformers支持大模型推理服务化部署
B. MindSpore Transformers是MindSpore面向大模型领域的使能套件
C. MindSpore Transformers基于MindSpore构建,支持分布式训练和分布式推理
D. 昇思MindSpore作为深度学习框架,下接如MindSpeed、MindIE的应用使能层,上接CANN异构计算架构的硬件使能层
正确答案:D
解析:A选项正确,它可以对接模型应用层的MindIE从而进行大模型的服务化部署;B选项同样正确,它依托于MindSpore的框架,基于该框架构建MindSpore Transformers是一个面向大模型Transformer结构系列的套件,它会提供一些业界常见的大模型,能够进行一行代码调用,实现开箱即用,同时其中预置多种微调算法来简化开发;再看C选项,由于套件基于框架构建,就会继承来自框架的能力,即分布式训练和推理,也正确;对于D选项,最底层是昇腾硬件,再往上是CANN异构计算架构,再往上是MindSpore深度学习框架,它能够对接调用基于CANN开发出的算子,再往上是应用使能层,即MindSpeed、MindIE等,通过它去调用或对接基于框架层开发出的模型等全流程,所以D选项描述顺序错误,应为上接MindSpeed、MindIE的应用使能层,下接CANN异构计算架构的硬件使能层。
2、一家小型科技公司想采用昇腾+CANN搭建了集群平台来运行其基于开源模型自主研发的大模型应用,现在正在采购对应的计算服务器,假设目前该公司想采用Atlas 800TA2服务器进行训练适配,模型大小为671B,服务器A型一共内置8个NPU芯片,每块芯片显存为64G,该公司的微调方法为LORA(FP16),假设调节的参数量较小,相对于原模型可以忽略不计,那么其至少需要准备几台Atlas 800 TA2服务器?(单选题)
A.1台服务器 B.2台服务器 C.3台服务器 D.4台服务器
正确答案:C
解析:本题考察微调的显存计算,LORA微调的理想显存占用是模型权重占用+优化器状态占用,本题已经给出假设调节的参数量较小,相对于原模型可以忽略不计,所以只需要计算模型权重占用的显存即可,又模型显存的占用是用模型的参数量大小*采用的精度,本题采用的是FP16精度,它对应2个字节,所以占用显存为671B*2(B/param)*1024^3/1024^9=1342G,而每台服务器是8*64G=512G的显存,所以至少需要3台Atlas 800 TA 2服务器,因此选C。
3、昇腾AI处理器使用的高性能集合通信库被称为HCCL,是华为集合通信库中的重要组成部分,现在某分布式训练系统中,RDMA通信带宽速率低于预期,并注意到昇腾网卡与Switch(交换机)的QoS不匹配,初步判断是和网卡配置的PFC优先级不相同。通过调整以下哪个配置能正确解决这个情况?(单选题)
A.HCCL_RDMA_TC B.HCCL_INTRA_ROCE_ENABLE
C.HCCL_RDMA_SL D.HCCL_BUFFSIZE
正确答案:C
解析:本题考察HCCL中参数的配置,先看A选项,HCCL_RDMA_TC参数是用于配置RDMA网卡的traffic class,这个环境变量对应的是RoCE报文中的DSCP,DSCP是可以对IP数据包进行服务差分标记的,可以解决与交换机的QoS不匹配的问题,但与PFC优先级没有关系,因此排除A;再看B,HCCL_INTRA_ROCE_ENABLE参数是用来配置服务器里是否使用ROCE环路进行多卡间通信,如果用户使用虚拟化场景或是当PCIE带宽不足的时候就可以通过设置ENABLE参数,本选项与题干也不匹配,故排除;C项HCCL_RDMA_SL是用于配置RDMA网卡的service level,这个值需要和PFC优先级一致,如果不一致可能导致性能劣化,因此正确;D项HCCL_BUFFSIZE用来控制两个NPU之间共享数据的缓冲区大小,与QoS不匹配问题和PFC优先级都没有关系,因此本题选C。
4、昇腾解决方案中,所有的Atlas服务器可以提供AI处理器容器化和虚拟化支持,以下哪些选项是正确的?(多选题)
A.可以实现多个用户同时复用一台服务器资源
B.一台Atlas 80OT A2服务器有8块NPU,最多支持8名用户申请虚拟化资源
C.在使用Ascend Docker Runtime进行昇腾卡挂载时,一个容器内可以挂载多个卡或者单卡
D.虚拟化分配昇腾硬件单元的最小单位是NPU,一个vNPU包含一个或多个NPU
正确答案:AC
解析:A选项正确,虚拟化和容器化目的是实现多个用户同时复用一台服务器资源;B选项前半句正确,后半句“最多支持8名用户”有误,当采用虚拟化之后可以支持多于卡数的用户使用,所以可以支持多于8名用户申请虚拟化资源;C选项正确,在容器启动的时候可以指定启用哪些卡,所以可以挂载多个卡或者单卡;D选项虚拟化分配昇腾硬件单元的最小单位是AI Core,而不是NPU,错误,因此本题选AC。
5、MindSpore Transformers大模型套件是昇腾全栈AI方案分布式计算架构中的重要组成部分,在使用MindSpore Transformers开发大语言模型时,需要实现以下哪些类?(多选题)
A.模型启动类 B.模型配置类 C.模型类 D.分词器类
正确答案:BCD
解析:在构建大模型时,首先需要知道大模型的结构是什么样的,比如是decoder结构还是encoder-decoder结构,所以本身模型需要有一个类去构建结构,除此之外模型有超参的概念,像大模型或者大语言模型LLM会包含hidden size, number of layers, multi-head attention的头数等,这些都是关于模型结构本身的超参信息,会归类于模型配置这一方面,再者是关于模型输入输出方面,输入输出一般是文字类型的内容,那如何转换为模型本身可以接受的输入或能够参与计算呢?一般需要一个词表,将文字类型的token映射到对应的数字索引id,然后进一步转化对应的embedding,这个过程一般称为tokenization,所以还需要分词器来实现。而在后来可能需要从模型输入到模型构建再到模型启动,这里的启动本质上是如何去启动训练、微调或推理的任务。因此对于A选项模型启动类,不需要自己构建,在MindSpore Transformers里会统一提供一个执行脚本叫run_mindformers,直接调用该脚本实现任务拉起,所以A是不需要的;对于B选项对应上文提到的模型的超参,里面包含模型结构所有信息,而在构建模型配置类时也可以继承里面的PretrainedConfig已提供的基类进行实现,因此需要;对于C选项模型类是模型结构相关的,也是需要实现的;而对于D项分词器类,即Tokenizer,也是需要实现的,往往在实现过程中也可以继承PreTrainedTokenizer或者PreTrainedTokenizerFast,因此本题选BCD。
6、昇腾全栈解决方案需要解决人工智能在业务中的实际部署落地方案,在业务中部署模型至少需要包括:
(A)业务流程场景分析 (B)微调数据准备 (C)模型选型
(D)训练调优 (E)推理部署 (F)应用集成
分析以上步骤,以下大模型业务流程顺序部署流程正确的是?(多选题)
A.准备阶段:A->B->C B.训练部署阶段:F->D->E
C.准备阶段:A->C->B D.训练部署阶段:D->E->F
正确答案:CD
解析:首先先看AC两选项,准备阶段对应前三个步骤((A)(B)(C)),一般需要先进行业务流程场景分析,然后进行模型选型,因为是根据场景分析的结果来选型模型,在选定模型之后再进行微调数据准备,因为需要的微调数据和选定的模型有较大的关系,包括文件的格式等等,因此在AC选项中选C;再看BD选项,训练和部署阶段一般先进行训练调优,然后进行推理部署,推理部署测试没问题之后才进行应用集成,因此BD中选D,本题正确答案为CD。
Part 2 模型训练与调优模块(共8题):
1、在医疗影像分析领域,深度卷积神经网络(CNN)被广泛应用于医学图像分类,以辅助医生进行疾病诊断。某同学在训练深度CNN进行医学图像分类时,发现训练集准确率达98%,但验证集准确率在70%波动,且混淆矩阵显示模型对少数类(如恶性肿瘤)召回率极低。此时最应优先采取的措施是哪一项?(单选题)
A.对全量数据应用MixUp数据增强
B.在网络末端添加自注意力机制
C.采用类别加权交叉熵损失函数
D.在卷积层后增加BatchNorm层
正确答案:C
解析:首先看A选项,MixUp数据增强通过线性插值两个样本集标签生成新的样本,这样可以增加数据的多样性,可以缓解过拟合,然而MixUp数据增强技术并不能直接解决少数类别的识别问题;然后看B项,自注意力机制可以帮助模型更好地关注输入数据中重要部分从而提高模型的表现,该方法可能有助于提高整体性能但是对于解决少数类别的识别问题也是有限的;C选项类别加权交叉熵损失函数可以为不同的类别赋予不同的权重,使模型可以更加关注少数类别的样本,该方法可以直接提升模型对于少数类别的识别能力,同时也有助于缓解模型中过拟合的问题;D选项中BatchNorm层可以加速训练过程并且提高模型稳定性,但是它主要作用于减少内部协变量偏移,对于文中训练集效果比较好验证集效果较差的过拟合现象和少数类别的识别问题的帮助是相对较小的,因此本题选C。
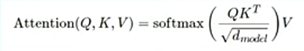
2、注意力机制能够帮助模型在输入序列中选择性关注某些部分,从而提高模型表示能力。根据上图公式,在基于MindSpore计算scaled dot-product attention的过程中,下列关键步骤排序正确的选项是哪一个?(单选题)
from mindspore import ops
1.通过attn_mask进行注意力掩码
if attn_mask is not None:
attn = attn.masked_fill(attn_mask,-1e9)
2.注意力权重与value做矩阵乘
output = ops.matmul(attn, value)
3.计算![]() 得到scaling factor后,通过ops.matmul计算query和key的点积,并除以scaling factor
得到scaling factor后,通过ops.matmul计算query和key的点积,并除以scaling factor
attn = ops.matmul(query, key.swapaxes(-2,-1)/ scaling_factor)
4. softmax使权重保证在0-1之间
attn = self.softmax(attn)
A.3412 B.3142 C.1342 D.4321
正确答案:B
解析:在公式中,从计算的顺序上先是Q(即文字表述中的query)*K的转置矩阵再除以d_model(它一般对应hidden size,也就是模型本身的dimension)的开方作为factor,所以按照该流程第一步应做Q和K的转置矩阵相乘再除以factor,也就是3,因此排除CD,然后再看1和4的顺序,1主要做掩码,4主要是softmax,结论是掩码需要在softmax之前,它是帮助识别仅作为占位但是没有任何语义意义的token,具体如何得到该结论其实可以看题目中代码的实现,序号1中可看出是masked_fill,意思是它去把QK做点积之后里面padding对应的位置用1*10^9的形式进行填充,之所以它填的负数如此大是为了接下来softmax(softmax计算时是e的x次方),通过这样的形式将值转换为0,所以按照代码实现的填充数值来看,先1后4,整个顺序是3142,因此本题选B。

3、如上图代码所示,在基于MindSpore框架实现Transformer的Feed-Forward Network中,我们在“******”处应该填写什么代码,从而对输入进行非线性变换?(单选题)
A.空白1: self.activation = nn.GELU()
空白2: x = self.activation(x)
B.空白1: self.dense = nn.Dense(in_features, hidden_features)
空白2: x = self.dense(x)
C.空白1: self.dropout = nn.Dropout(p=1.0-keep_prob)
空白2: x = self.dropout(x)
D.空白1: self.attn_matmul_v = ops.BatchMatMul()
空白2: x = self.attn_matmul_v(x)
正确答案:A
解析:本题考察前馈神经网络的结构与代码实现,前馈神经网络首先有全连接层,将维度从低维映射到高维,然后经过一个激活函数做非线性变换,然后再有linear projection全连接层将高维映射到低维,这样的形式保证神经网络输入和输出的shape是一样的,然后回到代码里看,在图里偏下方部分的construct,是定义好的前馈神经网络正向计算的逻辑,最开始已有self.dense了,即第一层的全连接已实现,然后看到*号下面的dropout和dense2,因此需要在*中填充的是一前一后全连接层中间的非线性变换的激活函数。A选项是过程中进行GELU激活函数,B选项还是做一个线性层,C选项是dropout,但是dropout在代码中已经实现了,而D选项做BatchMatMul批归一化,也不是在前馈神经网络中涉及到的内容,因此本题主要需要找到激活函数,即选A。

4、目前已有基于MindSpore实现的网络Network,并定义了一个函数(run)用于进行模型的正向计算,代码实现如上图所示。某同学发现代码运行较慢,计划开启静态图模式进行加速,以下哪种方式描述是错误的?(单选题)
A.使用mindspore.set_context(mode=mindspore.GRAPH_MODE)进行全局设置
B.在run函数上使用mindspore.jit修饰器,这样在调用该函数时,该模块自动被编译为静态图
C.使用mindspore.jit_class()进行全局设置
D.在调用run函数前,添加一行run_with_jit=mindspore.jit(run),通过函数变换方式调用jit方法
正确答案:C
解析:A选项在mindspore的set_context中将mode设置为GRAPH_MODE,即静态图模式进行全局设置,正确,在设置之后全局代码就会以静态图的方式编译然后执行;在B选项中在run函数上使用mindspore.jit修饰器,它作用是即时编译,在被修饰的函数会以图编译的方式进行性能提升,该方法适用于希望局部提升性能但是在其他部分仍希望保证调优的灵活度,因此这样的即时编译是一个很合适的方法;再看C选项,mindspore.jit_class()进行全局设置,它其实主要的方式是像B一样做一个装饰器,然后装饰到一般是模型的类或者nn.cell里,所以C表述不正确;D选项是另一种方法,除了在run本身函数上面加装饰器,也可以通过run_with_jit,即mindspore.jit()括弧里添加需装饰的函数来实行即时编译,因此本题选C。
5、某同学基于MindSpore实现ResNet网络,并使用CIFAR-10数据集来进行训练的时候,进行了以下数据预处理操作:
1.加载下载并解压好的Cifar10数据集
2.将图片调整到统一尺寸大小
3.原本图片像素值大小在0到255之间,需要调整至0到1区间
4.对图片数据进行归一化处理
5.输入图片的shape原本为(height, width, channel),应变成(channel, height, width)
6.对训练数据需要进行随机裁剪,增加模型的泛化性
7.对训练数据需要进行随机水平翻转,增加模型的泛化性
以下MindSpore的哪些数据预处理方法可用在上述操作中?(多选题)
A. mindspore.dataset.vision.Resize
B. mindspore.dataset.vision.Invert
C. mindspore.dataset.vision.Rescale
D. mindspore.dataset.vision.HWC2CHW
正确答案:ACD
解析:A选项Resize作用是将图片大小尺寸进行调整,对应题中操作的序号2,因此正确;B选项是对色彩进行反转,在题目描述中未出现该内容,因此不选;C选项Rescale是将图像数据中intensity的数值进行缩放,在题目中有序号3是将图像像素值从0到255之间,调整至0到1区间,是把值除以255,因此正确;D选项HWC2CHW是指HeightWidthChanneltoChannelHeightWidth,对应题目中序号5的描述,通过它对shape变换,同样正确,因此本题选ACD。
6、在医疗影像分类任务中,正样本(患病)占比仅5%,负样本占比95%。训练时模型对负样本预测准确率高,但对正样本几乎无法识别。以下哪些方法可以有效缓解此问题?(多选题)
A.对负样本进行欠采样(Under-sampling)
B.在损失函数中为不同类别分配权重(如增加正样本的权重)
C.对正样本进行数据增强(Data Augmentation)
D.对输入数据进行标准化(Normalization)
正确答案:ABC
解析:由题意正样本(患病)占比仅5%,负样本占比95%,负样本占比远大于正样本,数据是不平衡的,模型对于较多样本预测准确率高,对于占比较小的样本无法识别。针对数据不平衡问题,一般是从数据和算法两个层面缓解该问题。数据层面,一般是对于较多样本采用欠采样,对于较少样本采用过采样,以平衡他们的关系;对于算法层面,主要是调节损失函数。在选项中ACD都是数据层面,A项对负样本进行欠采样,可以减少负样本数目,可缓解数据不平衡问题;C项通过数据增强可以增加正样本的数目,也正确;D项是数据预处理常规操作,对于解决数据不平衡问题没有帮助;最后看B项,它是从算法层面进行缓解,在损失函数中增加正样本的权重就可以增加对于正样本的关注,相当于对困难数据的挖掘,也可以缓解数据不平衡问题,因此本题选ABC。
7、某同学基于MindSpore构造神经网络层,并实例化为net后,希望获取网络层的参数。已知网络层中有四个参数: w、b、mean、var,其中w和b为可训练参数,mean和var为不可训练参数。以下操作正确的是哪几项?(多选题)
A.单独获取b的参数值:net.b.asnumpy()
B.获取mean和var的参数信息(包含名称、Tensor形状、数据类型等): net.trainable_params()
C.获取w和b的参数信息(包含名称、Tensor形状、数据类型等): net.trainable_params()
D.只获取b和var的参数值: net.get_parameters()
正确答案:AC
解析:本题中有四个参数,w对应weight,b对应bias偏置,还有mean和variance,A项是希望获取b的参数值,它的操作正确,通过net把b的参数进行实例化,同时通过asnumpy将其转换为numpy数组,从而看到里面具体数值,可打印出来;B项是获取mean和variance的信息,但是这里用到的接口是trainable_params,它本质上找的是网络中可训练(参与训练)的参数,mean和variance不参与其中,其实没有办法通过trainable_params获取到,因此不可行;C项是获取w和b,接口同样是trainable_params,相当于w和b也同时是可训练的参数,符合题意中w和b为可训练参数,因此可以获取到信息;D项获取b和variance参数值,使用get_parameters,get_parameters的方式是获取网络中所有参数,通过它得出参数的名称、数据类型以及shape,但是无法通过该方式获取数值,因此不可行,本题选AC。
8、在基于MindSpore构建ResNet网络时,主要可以分解为以下步骤:
1.通过类(class)构建残差块;
2.通过make_layer函数实现残差块堆叠;
3.通过类构建ResNet50模型,实现5个卷积结构,并在最后添加池化、全连接、softmax层;
对构建ResNet50网络的细节描述,哪些是正确的?(多选题)
A.ResNet50网络层数多,通过nn.SequentialCell进行模型堆叠,可避免重复编写代码
B.在残差块运算中,我们将输入设为x,网络层的输出为F(x),ResNet残差块最终输出为x+F(x);我们不需要考虑x与F(x)的shape一致,可以直接进行加和,得到输出
C.在构建残差块时,可继承Cell类,并重写_init_方法与construct方法
D.ResNet50网络的最后一层为全连接层(nn.Dense),它的输出channel为分类的类别数
正确答案:ACD
解析:A项ResNet50属于模型层数较多的模型,而且残差块的实现结构都是相似的,可能就是channel的值不一样,所以可以事先将模型架构搭出,每次复用模型架构进行堆叠,即通过nn.SequentialCell方式实现模型构建,它在过程中传入类似于列表,执行时通过列表顺序将模型各个层构建;B项中假设输入是x,经过网络层输出F(x),残差最重要的一点是有个加和的过程,但是选项中提到“不需要考虑x与F(x)的shape一致,可以直接进行加和”是错误的,因为本身是做直接相加的方式,相加需要保证shape一致,否则会出现报错;C项中构建残差块就是通过类构建,继承nn.Cell类,然后通过重写_init_与construct方式来构建网络,一个是实例化网络层,一个是定义正向计算逻辑,正确;D项中ResNet50网络的最后一层为全连接层,一般在这里做线性映射,它的输出一般对应分类的类别数,因为最后对应每个类要计算类似probability,然后选中概率最高的标签作为预测的结果,因此也正确,本题选ACD。
Part 3 模型推理与应用模块(共6题):
1、某同学正在基于MindSpore框架完成BERT情感分类任务,即预测输入语句的感情色彩(positive、negative、neutral),已知输入序列为“[CLS] a visually stunning rumination on love [SEP]”,该同学需要将以下哪一部分的输出放入到分类器中?(单选题)
A.[SEP]
B. a visually stunning rumination on love
C. visually stunning
D.[CLS]
正确答案:D
解析:情感分类的任务本质上需要获取到句子的整体信息,对此分析情感是积极、消极还是中性的,BERT本身事务是将其中每个Token经过网络层得到对应的输出,在此题中为了获取到整个句子信息,一般选择CLS的token(CLS一般是class的缩写),默认它在整个训练过程中是可以学习到整个句子的语义和表达,因此本题选D。
2、在计算机视觉领域,Transformer架构因其强大的特征提取能力而受到广泛关注。Swin Transformer作为其中的一种创新设计,通过引入局部窗口内的自注意力机制,能够在保持计算效率的同时,有效捕捉图像中的长距离依赖关系。有研究者使用Swin Transformer时,将窗口大小从7×7改为14×14后,模型在密集预测任务上细节丢失严重,根本原因在于?(单选题)
A.全局注意力计算复杂度增加
B.局部归纳偏置被弱化
C.窗口移位策略失效
D.位置编码分辨率不足
正确答案:B
解析:Swin Transformer是一种基于Transformer的视觉模型,目的是为了解决传统transformer模型在计算机视觉任务中的高计算复杂度问题,题目要求窗口大小从7×7改为14×14后,模型在密集预测任务上细节丢失严重的根本原因。首先看A项,全局注意力计算通常涉及到整个图像或者序列的,就像题干中Swin Transformer是关注局部窗口内的自注意力机制,所以当窗口变大之后,不会影响全局注意力计算的复杂度,因此A错误;B项中局部归纳偏置通常是指模型对于局部特征的关注,当窗口大小从7×7改为14×14后,它每个窗口覆盖的区域变大,这意味着每个窗口的局部特征变少,导致局部细节的丢失,因此正确;C项窗口移位策略是Swin Transformer重要的机制,用于确保跨窗口之间的信息交互,虽然窗口大小变化确实会影响窗口移位策略效果,但是窗口移位策略并不是导致细节丢失的原因;D项位置编码提供空间信息,位置编码分辨率是位置编码可以区分最小的位置差异,窗口大小变化并不会直接影响位置编码的分辨率,位置编码分辨率仍然可以保持原有的分辨率,因此本题选B。
3、某团队基于MindSpore框架构建了一个ChatGLM2对话生成模型,该模型继承ChatGLM的优点,还在多个方面进行了创新和优化。其中一个重要的优化就是采用了multi-query attention (MQA)机制。以下选项中哪一项对MQA描述是错误的?(单选题)
A.Multi-query attention(MQA)和multi-head attention (MHA)的主要差别在于:在MQA中,不同的attention head共享一份keys和values权重
B.后续在MQA基础上又演变出了grouped-query attention (GQA),将query进行分组,每组共享一份key和value
C.MQA主要想要解决的是Transformer类模型推理慢的问题
D.MQA能够有效加快推理的速度,并且同时提升模型的能力
正确答案:D
解析:从名字上看,multi-head attention有多个注意力头,在每个头下都会进行第一模块所述的QK点积等等计算,但是它有个问题,每一次计算都需要存当前K和V,而且本质上在推的时候是基于之前的信息不断预测下一个token,这会导致本身缓存较多以及推理速度有待改进的问题,因此诞生出multi-query attention,multi-query attention的方式是多个注意力头的query仍然保留,但是多个头仅共享一组的K和V,由此减少K、V的计算,从而提速,但是这样的牺牲会换来模型效果的降低,因此在未来又会做一个综合,即头数尽量减少K和V的组,但不至于极端到只剩下一对,所以出现grouped-query attention方式,即保留少数的K-V对,每一对有多个query共享这一组K、V,通过这样形式取得平衡和改进。结合以上内容再看选项,A项MQA和MHA差距点在于共享一组K、V上,所以A正确;B项GQA在上文中已提到,正确;C项提到MQA解决推理缓慢的问题以提速,正确;D项加快推理的速度和提升模型能力无法同时满足,加快推理速度同时模型能力会有所损失,因此本题选D。
4、在现代智能监控和物联网应用中,边缘计算扮演着越来越重要的角色。为了实现实时分析和响应,需要在边缘设备(如摄像头)上部署目标检测模型。然而,这些设备通常资源有限,存储空间和计算能力都受到严格限制。因此,如何在保持较高检测精度的同时减小模型体积,成为了一个亟待解决的问题。以下哪些方法可以减少模型体积同时保证精度损失较小?(多选题)
A.将模型从FP16转换为INT8量化
B.使用知识蒸馏(Knowledge Distillation)训练轻量学生模型
C.启用动态批处理(Dynamic Batching)
D.对输入图像进行下采样至更低分辨率
正确答案:AB
解析:A项是从浮点域转换为整型域的模型压缩技术,它可以直接压缩模型的体积,这样的转化数据量减少一半,可以降低内存和带宽的占用,同时现代模型量化技术可以保持较高的精度;B项是将大型深度学习网络知识蒸馏到更小、更轻量的学生模型中,在训练过程中学生模型的目标是最小化教师模型的预测结果的误差,同时最小化学生模型本身损失函数,因此也有减少模型体积并保证精度损失较小的效果;C项是根据输入数据的实时需求来调整批量大小,主要提升计算效率和增加吞吐量,用来优化计算速度,与本题的减少模型体积无关;D项对于图像下采样可以减少图像的像素数量,因而可以减少计算量,但同时下采样还有一个效果,即增加感受野,来提取图像的更高层次的抽象特征,这可能降低输入信息量,也可能导致检测精度显著降低,不符合题干要求,因此本题选AB。
5、在当今的深度学习领域,大型语言模型因其强大的性能而被广泛应用。然而,这些模型往往需要大量的计算资源和内存来运行。现在,有研究者部署一个大型语言模型时,NPU显存不足导致推理中断。以下哪些方法能直接减少显存占用?(多选题)
A.改用量化后的模型
B.采用梯度检查点(Gradient Checkpointing)
C.对模型进行分块加载
D.使用低秩适配器(LoRA)微调模型
正确答案:AC
解析:A项改用量化后的模型与前一题模型量化考察点一样,它的模型体积减少,可以降低显存占用,因此正确;B项是模型训练过程中减少内存占用的技术,与题目中推理应用部署不符;C项是对模型分块加载,即在模型推理部署时可以动态管理显存,减少显存占用;D项LoRA是训练过程中参数高效微调技术,与推理时显存占用无关,因此本题选AC。
6、在当今的电子商务环境中,快速响应的在线商品推荐系统对于提升用户体验和增加销售转化率至关重要。为了满足这一需求,某电商平台对其在线商品推荐系统进行了性能评估,并发现了一个关键问题:该系统需要在50毫秒内返回推理结果以确保流畅的用户体验,然而,当前的模型推理耗时却达到了120毫秒,远远超过了预期目标。因此,急需采取有效的优化措施来缩短推理时间。以下哪些优化措施是可行的?(多选题)
A.模型量化(Quantization)
B.层融合(Layer Fusion)
C.使用更复杂的特征工程
D.对部分请求缓存历史推理结果
正确答案:ABD
解析:A项模型量化可以减少模型计算量,并且降低带宽和内存的占用,因此正确;B项层融合是将多个层或是多个连续操作合并为一个复合操作来减少计算和内存开销,提升模型推理效率,因此也正确;C项特征工程涵盖关于数据获取、数据预处理、特征构建与提取、选择转换和监控评价以及错误分析到模型改进的全方位流程,如果使用更复杂的特征流程,可能增加推理时间;D项部分请求缓存适用于重复请求的场景,像在线商品推荐系统中的热门商品就非常适用缓存历史推理结果,因此本题选ABD。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐



 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)