实锤了,华为云CloudMatrix384昇腾AI云服务单卡吞吐超越H100
提供了一个垂直集成的软件堆栈,包括驱动程序、运行时和库,简化了开发人员与昇腾硬件的交互,有效促进了软硬件协同设计,并且最大限度地提高了昇腾架构上应用程序的性能。,这是一种全新的软硬件协同设计理念,旨在构建一个“全对等、高带宽、低时延”的硬件底座,并在此基础之上打造一个深度优化、与硬件能力紧耦合的。颠覆的时代,需要颠覆的思维、颠覆的路径,具有颠覆精神的开拓者。具备高密、高速、高效的特点,通过全面的架


今年春节过后,国内多地掀起了一股DeepSeek一体机采购热潮。与一家金融机构的CIO谈及此事,他十分感慨地表示:“DeepSeek大模型的出现,大大降低了AI推理的门槛,现在就看AI基础设施给不给力了!”他话锋一转:“可你看,从最初的‘一卡难求’,到后来不得不委曲求全地采用‘阉割版’的国外GPU卡,我们期盼具有真正替代能力的‘中国方案’,至少给我们多一种选择。”
相信与这位金融行业CIO持相同观点的中国企业用户不在少数。但大家也都心知肚明,从历史积累、技术创新、制造工艺,乃至生态建设、应用验证等多个维度衡量,GPU卡单卡性能的提升犹如“华山一条道”,后来者想要超越并非一日之功。好消息是,基于CloudMatrix384超节点架构的华为云新一代昇腾AI云服务已全面上线,实测数据显示,其单卡推理吞吐量达2300Tokens/s,较传统架构提升近4倍,甚至已经甩开了英伟达H100。
这或许为未来AI算力之争推开了一扇新的窗子,不必再执着于制程纳米数,而是要打赢“架构+互联+软件”这场系统之战。当英伟达还在努力地打造更好的锤子时,华为已经在重建整个工具箱。
AI基础设施构建路径分化
机会来了
从训练到推理,AI算力需求的范式转移将引发新的行业和应用变革。Stanford HAI发布的《逻辑推理AI市场全景解析(2025版)》中指出,全球AI技术已经进入“推理优先”的新周期,2025年逻辑推理类AI软件市场规模将超过480亿美元。AI推理的飞速发展对AI基础设施提出了前所未有的高要求,尤其是在高吞吐、低延迟、可扩展性、能效比和安全合规性等方面。
为了满足AI算力需求,AI基础设施的构建路径逐渐出现了分化:国外厂商的单卡算力强劲,且生态成熟,但受地缘政治等客观因素影响,中国用户在应用时会受到种种限制;国内厂商以华为为代表,在制程相对落后的情况下另辟蹊径,通过架构级创新,以高效的集群媲美甚至反超国外厂商单卡的高性能。华为基于CloudMatrix下一代AI数据中心架构,在行业用户中落地了首个生产级实现——CloudMatrix384,这是一种全新的软硬件协同设计理念,旨在构建一个“全对等、高带宽、低时延”的硬件底座,并在此基础之上打造一个深度优化、与硬件能力紧耦合的LLM服务系统,即CloudMatrix-Infer,从而突破了传统架构的瓶颈。
华为的巧思、巧技,巧妙地实现了弯道超车。
单卡vs.集群
选择来了
据了解,基于华为CloudMatrix384超节点架构的新一代昇腾AI云服务已在乌兰察布、和林格尔、贵安、芜湖全面上线,为科大讯飞、新浪、硅基流动、面壁智能、中科院、360等多家企业和机构提供澎湃算力,其领先的性能优势在行业应用中变得更加具象和聚焦。CloudMatrix与昇腾AI云服务为何能如此珠联璧合?
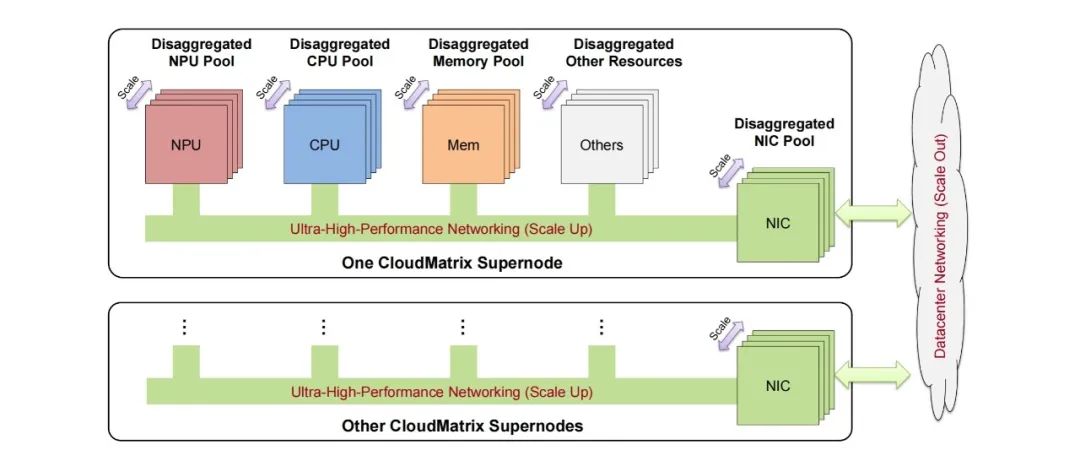
华为CloudMatrix架构:重构AI数据中心基础设施
1.不争单卡之短长,掀起集群革命
此次CloudMatrix384昇腾AI云服务单卡推理吞吐超越英伟达H100,是首次在关键指标上的超越,证明了在AI基础设施领域,架构级创新是一条可行之路。CloudMatrix384具备高密、高速、高效的特点,通过全面的架构创新,在算力、互联带宽、内存带宽等方面实现了领先。
首先,CloudMatrix384超节点架构通过MatrixLink高速网络实现了384颗昇腾NPU和192颗鲲鹏CPU全对等互联,形成一台超级“AI服务器”,构成了高性能计算单元。CloudMatrix是专为满足现代大规模AI工作负载的需求而设计的,定义了AI原生基础设施的新范式。它秉承完全点对点高带宽互联和细粒度资源分解的原则,突破了传统的以CPU为中心的层级设计,支持所有异构系统组件,包括NPU、CPU、DRAM、SSD、NIC和特定领域加速器之间的直接高性能通信,且无需CPU中介。凭借超高带宽、低延迟的统一总线网络,它促进了高效的全系统数据传输和协调。
其次,CloudMatrix384这种“一卡一专家”的并行推理模式,非常贴合混合专家模型(MoE)进行深度优化,其可承载384个专家模型同步运行。在资源调度层面,实现“一卡一算子任务”的细粒度控制,使算力有效使用率(MFU)提升50%以上;在可扩展性方面,支持432个节点级联构建16万卡集群,并且创新性地实现了“日推夜训”的训推算力动态分配方案。
最后,将预填充(Prefill)和解码(Decode)分离,使得吞吐提升3倍。华为联合硅基流动发表的论文《Serving Large Language Models on Huawei CloudMatrix384》显示:在Prefill阶段,在理想的专家负载均衡(Perfect EPLB)条件下,CloudMatrix-Infer在昇腾910C上实现了6,688 Tokens/s的单卡吞吐,计算效率达到4.45 tokens/s/TFLOPS,显著高于SGLang on H100的3.75和DeepSeek on H800的3.96。在Decode阶段,在满足低于50ms TPOT(Time-Per-Output-Token)延迟的条件下,CloudMatrix-Infer的单卡吞吐达到1,943 tokens/s,计算效率为1.29 tokens/s/TFLOPS,也超越了SGLang on H100的1.10和DeepSeek on H800的1.17。
上述数据显示,在运行大规模MoE模型时,华为CloudMatrix384实现了业界领先的硬件利用效率。同时,它还能灵活地兼顾吞吐与延迟,在严苛的15ms TPOT约束条件下,依然能保持538 tokens/s的吞吐,展现了其在不同服务等级下的强大适应能力。
2.全栈创新,软件赋能
华为为昇腾NPU开发了神经网络计算架构CANN(compute architecture for neural networks)。人们经常拿它与CUDA相提并论。CANN充当中间软件层,用来支撑高级AI框架(如PyTorch 和TensorFlow)与昇腾NPU的低级硬件接口之间的高效集成。CANN提供了一个垂直集成的软件堆栈,包括驱动程序、运行时和库,简化了开发人员与昇腾硬件的交互,有效促进了软硬件协同设计,并且最大限度地提高了昇腾架构上应用程序的性能。CANN还广泛支持主流的AI框架,降低了AI项目采用昇腾NPU的门槛。
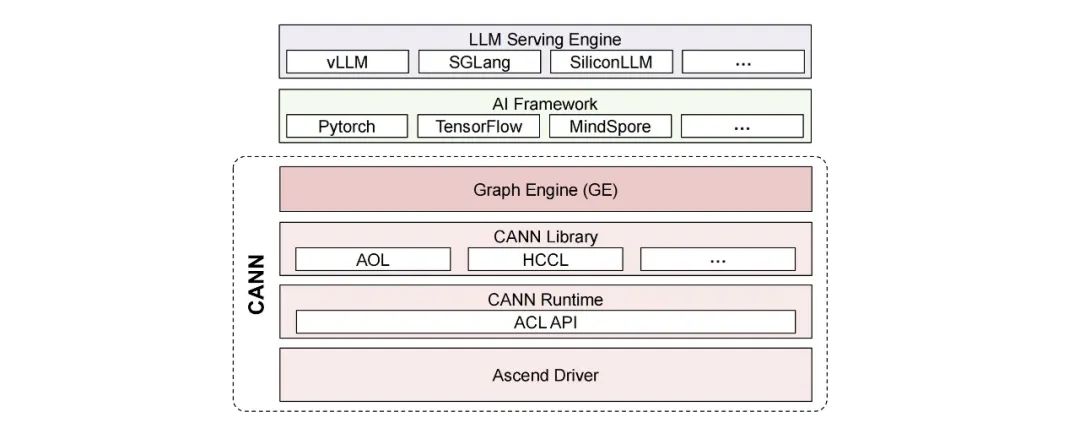
华为昇腾NPU的CANN软件栈
在云中,CloudMatrix384能够游刃有余,因为华为云提供了包括MatrixResource、MatrixLink、MatrixCompute、MatrixContainer等在内的完善的基础设施软件,抽象硬件的复杂性,并通过标准云API实现无缝的资源编排。再加上ModelArts、ModelArts Studio等,方便用户高效构建和部署大规模的AI应用程序。
华为基于系统性思维、架构级创新,为用户奉献上一台“超级AI计算机",而非简单的GPU堆叠,从根本上重塑了AI基础设施。
算力变革
华为来了
华为用数学补物理、非摩尔补摩尔,利用集群计算的原理,满足用户现在及未来的需求。或许你会说,这是华为的“被逼无奈之举”,但历史上又有多少披荆斩棘、绝处逢生的例子。在AI基础设施领域,实测的性能指标、用户的应用实践都有力地证明了,华为云CloudMatrix384昇腾AI云服务不仅可用,而且好用。
在AI颠覆一切的时代,AI在企业中的落地,以及AI基础设施的演进与创新,还都处于起步阶段。颠覆的时代,需要颠覆的思维、颠覆的路径,具有颠覆精神的开拓者。开辟集群、互联的路径,CloudMatrix384昇腾AI云服务只是一个开始,随着模型规模的持续膨胀、推理需求的快速增长,更大规模的超级节点、CPU资源的物理解耦、更细粒度的组件级解耦、混合自适应部署等,都将是新的挑战。
算力为舟,模型是楫。划向数智化的彼岸,华为云CloudMatrix昇腾AI云服务是劈波斩浪的一艘旗舰。
往期回顾
1
2
3
4


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)