【LLaMA-Factory】基本原理及昇腾下安装
阿里云DSW 提供多种 预装主流框架的镜像(类似Docker容器模板)。模块化设计(四大核心组件,官方为三个,不包含封装的WebUI)LlamaFactory 方案调研。LLaMA-Factory理论篇。LLaMA-Factory理论篇。LlamaFactory 框架。安装LLaMA-Factory。使用LLaMA-Factory。LlamaFactory 框架。安装LLaMA-Factory。使
·
文章目录
LLaMA-Factory理论篇
概述
- 背景
- 应用广泛:随着大模型(LLM)的快速发展,LLM微调的需求也不断增长,但是微调训练所需的软硬件资源消耗极大
- 开源模型涌现:更加先进高效的模型不断涌现,Hugging Face 等平台共享了数千个模型和数据集
- 微调挑战:LLM的参数量增长很快,每次微调的资源消耗巨大,
高效微调技术成为适应下游任务的关键 - 适应成本高:业界有很多高效微调方法和LLM,但是缺少一个的框架来进行适配和统一,并为用户提供友好的自定义界面
- 解决方法
- 核心矛盾:
先进高效的LLM相关技术与工业界的降本增效的AI需求之间需要进行大量重复性适配 - 解决方法:提供一个低代码和集成前沿高效训练套件的统一框架,解决高效微调技术的碎片化问题,降低训练成本和资源需求
- 核心矛盾:
- LLaMA-Factory
- 项目背景:由北航团队开源,专注于简化垂直行业大模型的微调与部署,支持从学术研究到企业应用的广泛场景。其开源社区活跃,月访问量超4万,被复旦大学、阿里云等机构采用
- 目的:实现一个能够进行高效微调的集成化LLM部署平台,LLaMA-Factory(Large Language Model Factory)是一个基于PyTorch综合性平台,集成先进的高效训练方法
- 功能:支持
100+主流语言模型(如LLaMA、ChatGLM、Qwen、Mistral等)的微调、训练、推理和评估。通过内置的Web UI(LlamaBoard),用户无需编码即可完成模型定制 - 核心目标:通过
模块化设计和先进算法集成,实现高效微调与开箱即用的定位。 - 核心价值:在于将学术界的先进高效LLM技术与工业界的降本增效的需求结合,通过可扩展的模块统一了多种高效的微调方法,能够在最少资源和高吞吐量的情况下对数百个LLM进行微调
- LLaMA-Factory特点
- 高效性
- 显存压缩:支持 QLoRA(量化低秩适配) 和 4/8-bit 量化 技术,能将模型训练显存需求降低至普通全参数微调的 1/10(例如,7B模型单卡仅需6GB显存)。
- 参数微调:采用 LoRA、DoRA 等方法,仅微调模型 0.1%-1% 的参数,显著减少计算量,同时保持性能接近全量微调。
- 分布式训练:集成 DeepSpeed、FSDP 等框架,支持多GPU并行训练,加速超大规模模型(如180B参数)的微调。
- 算法优化
- 训练加速:通过 GaLore(梯度低秩投影) 和 BAdam(块自适应优化器) 等技术,提升收敛速度,减少迭代次数。
- 推理加速:结合 vLLM 推理引擎,支持高吞吐量推理(如7B模型生成速度可达每秒30-50 token)
- 集成化
- 多模型支持:兼容 100+ 主流大模型(如LLaMA、ChatGLM、Qwen、Mistral等),无需为不同模型重写代码
- 训练方法集成:支持 全参数微调、 SFT(监督微调) 、 RLHF(人类反馈强化学习) 、 DPO(直接偏好优化) 等主流范式
- 低代码
- 用户仅需通过
配置文件(YAML)或Web界面选择模型、数据集和训练方法,无需手动编写训练循环。 - 示例:启动7B模型QLoRA微调仅需一条命令
python src/train_bash.py --model_name_or_path meta-llama/Llama-2-7b-hf --stage sft --dataset alpaca --template default --use_llamaboard
- 用户仅需通过
- 高效性
- LLaMA-Factory局限性
- 硬件依赖:超大规模模型(如180B)仍需高端GPU集群,普通用户可能受限于本地资源。
- 新模型适配延迟:最新模型需社区贡献适配代码,可能存在短期兼容性问题。
- 高阶定制门槛:虽然基础操作简单,但深度定制(如修改训练算法)仍需理解底层代码结构。
- LLaMA-Factory优化点
- 简化常见的训练方法
- 生成前馈(Generative Feedback)
- 原理:主要是利用模型生成的内容作为反馈,进一步调整模型参数,这种方法通常用于生成任务,并通过模型自身的输出来指导后续的优化
- 特点:适用于生成任务,但是过于依赖模型自身的生成能力,缺乏对人类偏好的直接考量
- 监督微调(Supervised Fine-Tuning, SFT)
- 原理:通过对高质量的数据输入和输出的标记数据集进行监督学习,使模型能够生成更符合任务要求的输出
- 特点:简单直接,但是需要高质量的标注数据,且可能无法充分捕捉到人类偏好
- 从人类反馈中学习的强化学习(Reinforcement Learning from Human Feedback, RLHF)
- 原理:训练一个奖励模型,用于评估模型生成的不同回答之间的优劣,再利用奖励模型的输出作为奖励信号,通过强化学习算法(如PPO)进一步优化模型策略。
- 特点:能够较好地对齐模型输出与人类偏好,但是复杂性较高,需要训练多个模型,并且计算资源消耗较大
- 直接偏好优化(Direct Preference Optimization, DPO)
- 原理:直接利用人类提供的偏好数据来优化模型,基于偏好数据设计损失函数,目标是最大化优选回答的概率,同时最小化非优选回答的概率
- 特点:通过直接优化偏好数据简化了优化过程,提高了效率,可能面临泛化能力不足的问题,特别是在验证集分布存在偏移的情况下
- 高效微调方法
- 高效优化技术:在保持成本最低的情况下对LLM的参数进行微调
- 高效计算方法:寻求减少LLM中所需计算的时间或空间
- 生成前馈(Generative Feedback)
- 简化常见的训练方法
- LLaMA-Factory中应用的微调方法
- 高效优化
- 冻结调整方法:涉及冻结大部分参数,同时在解码器层的小子集中微调剩余的参数
- 梯度低秩投影:将梯度投影到一个低维空间,以高效的方式进行全参数学习
- BAdam:利用块坐标下降(BCD)来高效地优化大量参数。
- 低秩自适应(LoRA):冻结所有预训练权重,并引入一对可训练的低秩矩阵到指定层。
- QLoRA:在LoRA基础上结合量化方法,减少内存的占用
- DoRA:将预训练权重分解为幅度和方向分量,并更新方向分量以提高性能
- 高效计算
- 混合精度训练:
- 激活检查点:
- Flash Attention:
- S 2 S^2 S2注意力:解决了扩展上下文与偏移稀疏注意力的挑战,从而减少了长上下文语言模型(LLM)微调时的内存使用
- 多种量化策略:通过使用低精度表示法来减少大型语言模型(LLM)的内存需求。
- Unstloth:结合了Triton,用于实现LoRA的反向传播,这减少了梯度下降期间的浮点运算(FLOPs),并加速了LoRA训练。
- 结果:LlamaFactory将这些技术无缝结合,形成一个整体结构,以提高LLM微调的效率。这导致内存占用从混合精度训练期间每参数18字节或半精度训练期间每参数8字节减少到仅每参数0.6字节
- 高效优化
LlamaFactory 框架
-
模块化设计(四大核心组件,官方为三个,不包含封装的WebUI)
- 模型加载器Model Loader
- 作用:用于加载适配模型,并对各种模型架构进行微调,从而支持多种大型语言模型(LLM)和视觉语言模型(VLM)
- 功能:模型初始化、架构修补(如适配不同注意力机制)、量化(4/8/16比特)、适配器加载(如LoRA权重)。
- 支持设备:CPU/GPU/NPU,兼容Hugging Face、vLLM等推理后端
- 数据工作者Data Worker
- 作用:将不同任务的数据集标准化为统一格式,从而实现在各种格式的数据集中微调模型。通过管道来整理和处理不同任务的数据,从而支持单轮和多轮对话
- 数据处理:加载、对齐(统一单轮/多轮对话格式)、合并(多数据集整合)、预处理(分词、截断)。
- 支持50+数据集,包括Alpaca、ShareGPT等
- 训练器Trainer
- 作用:应用高效的微调技术到不同的训练方法上,支持预训练、指令调整和偏好优化。
- 训练方法:集成SFT、RLHF、DPO等,支持分布式训练(DeepSpeed、FSDP)。
- 优化技术:LoRA+、PiSSA(主成分初始化适配器)等,提升收敛速度
- 扩展性:通过模块解耦设计,可灵活新增模型架构、数据集或训练算法
- 可视化UI界面LlamaBoard
- 用户能够配置并无代码地启动单独的LLM微调实例,并同步监控训练状态。
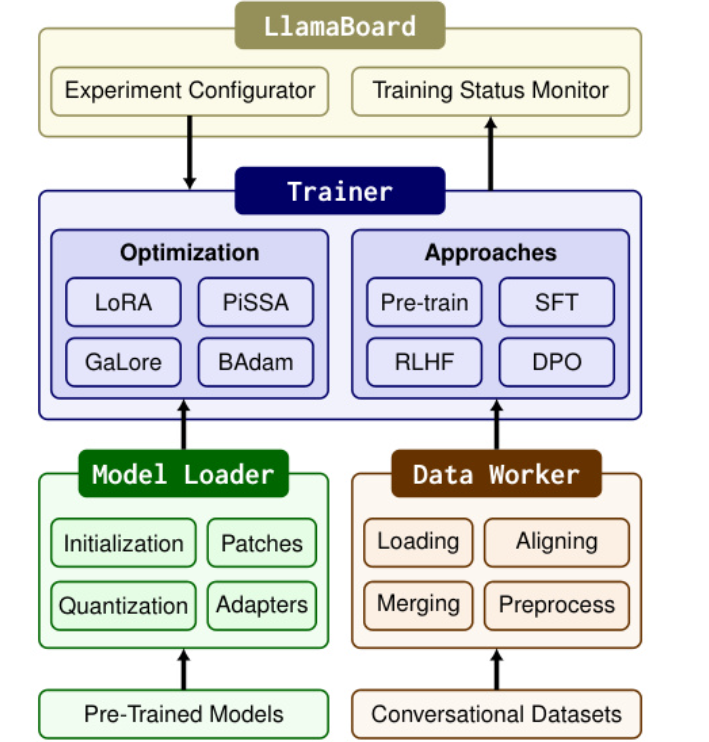
- 用户能够配置并无代码地启动单独的LLM微调实例,并同步监控训练状态。
- 模型加载器Model Loader
-
模型加载器的组成
- 模型初始化
- 原理:基于Transformer的self_classes加载预训练模型并初始化参数
- 注意点
- self_model_for_vision2seq类加载视觉语言模型,而其余部分则使用self_model_for_causallm类加载。
- 分词器与模型一起使用self_tokenizer类加载,但在tokenizer的词汇量超过嵌入层容量的情况下将调整该层,并用带噪声均值初始化的新参数进行初始化。
- RoPE缩放的缩放因子:将其计算为最大输入序列长度与模型上下文长度之比。
- 模型修补
- 原理:通过其Model Loader模块动态调整模型结构(如扩展嵌入层以适应更大的分词器词汇量,并使用带噪声的均值初始化新增参数)并结合参数高效微调技术(如LoRA的低秩矩阵适配器),在保持原始模型主干不变的情况下灵活适配不同任务需求
- 注意点:
- 为了启用S²注意力,使用monkey patch来替换模型的前向计算。并且使用原生类来启用Flash Attention
- 为了避免动态层过度分区,在DeepSpeed ZeRO阶段-3 下优化混合专家(MoE)模型时,将混合专家块设置为叶模块。
- 模型量化
- 通过 bitsandbytes 库动态将模型量化的位数调整为 8 位或 4 位,主要是双量化和NF4
- 双量化:是对量化常量再次进行量化以节省内存
- NF4:是一种改进的量化方法,能够确保每个量化仓中有相同数量的值,从而避免计算问题和异常值错误
- QLoRA方法:
- 一种高效的微调方法,通过将预训练的4位量化语言模型冻结,并将梯度反向传播到低秩适配器(LoRA)中来实现微调。利用了NF4和双量化的技术,能够在保持与16位全参数微调相当的性能的同时,显著减少内存需求。
- 引入了分页优化器,以防止梯度检查点期间内存峰值导致的内存不足错误
- 使用了16位BrainFloat作为计算数据类型,以提高计算效率
- 后训练量化(PTQ):
- PTQ是一种在模型训练完成后对其进行量化的技术,PTQ方法通常会降低模型精度,因此需要结合微调来恢复部分性能。
- 问题:由于直接对量化后的权重进行微调可能会导致不稳定性,因此这些模型仅与基于适配器的方法兼容。
- 通过 bitsandbytes 库动态将模型量化的位数调整为 8 位或 4 位,主要是双量化和NF4
- 适配器附加
- 原理:通过遍历模型层自动识别适当的层来附接适配器
- 优化点
- 用Unstloth的反向计算替换,以加速训练
- 根据计算设备的能力处理预训练模型的浮点精度。对于NVIDIA GPU,如果计算能力为8.0或更高,则采用bfloat16精度;否则,采用float16。
- 模型初始化
-
数据工作者的组成
- 数据集加载:
- 原理:利用Datasets库来加载数据,允许用户从Hugging Face Hub加载远程数据集或通过脚本读取本地数据集
- 优化点
- 使用Datasets库在数据处理期间显著减少了内存开销,并使用Arrow加速了样本查询。
- 默认下载整个数据集到本地,如果数据集太大,也能使用数据集流式处理,在不下载的情况下遍历它
- 数据集对齐:通过一个数据描述规范来表征数据集的结构来对数据集格式进行统一,从而将数据集转换为与各种任务兼容的标准结构。
- 数据集合并:基于统一的数据集结构对多个数据集进行高效合并
- 数据集预处理:提供了多种模型类型自动选择的聊天模板对文本生成模型进行微调
- 数据集加载:
-
训练器的组成
- 替换默认组件:将最先进的高效微调方法,包括LoRA+、GaLore和 BAdam集成到 Trainer 中
- 数据收集器:用来区分不同训练方法的trainer
- 模型共享的RLHF:动态切换使用目标函数训练的适配器和价值头,从而实现单个预训练模型能够同时作为策略模型、价值模型、参考模型和奖励模型
- 分布式训练:将上述训练器与DeepSpeed,从而能够采用数据并行性以充分利用计算设备的能力,并通过DeepSpeed ZeRO优化器,进一步减少内存消耗。
-
其他工具
- 推理过程中,重用来自 Data Worker 的聊天模板来构建模型输入
- 类似于OpenAI的API:利用了异步 LLM 引擎和 vLLM 的分页注意力,以提供高吞吐量的并发推理服务,便于将经过微调的 LLM 部署到各种应用程序中
- 模型评估:包括了用于评估LLM的多个指标,包括多选任务如MMLU、CMMLU和 C-Eval,以及计算文本相似度分数如BLEU-4 和 ROUGE
-
LLAmbard
- 作用:LLAmaFactory的统一接口,基于Gradio的统一用户界面,允许用户在不编写任何代码的情况下自定义LLM的微调。
- 功能
- 简单的配置:LLaMABOARD 允许我们通过与 Web 界面的交互自定义微调参数。我们为大多数用户推荐的参数提供了默认值,简化了配置过程。此外,用户可以在 Web UI 上预览数据集以验证它们。
- 可监控的训练: 训练过程中,训练日志和损失曲线将被可视化并实时更新,使用户能够监控训练进度。此功能提供有价值的见解来分析微调过程
- 灵活评估:LLAMABOARD支持在数据集上计算文本相似度分数,以自动评估模型或通过与它们聊天进行人工评估。
- 多语言支持:LLAMABOARD 提供了本地化文件,便于集成新语言以呈现界面。
-
模块间协作
- 用户通过LlamaBoard界面或参数文件配置参数后,Model Loader加载指定模型并注入适配器
- Data Worker处理输入数据并传递给Trainer启动训练
- 训练过程中,LlamaBoard实时监控状态,并支持中断后恢复
-
步骤
- 建立模型注册表:在该注册表中,模型加载器可以通过识别确切的层来精确地将适配器附加到预训练模型上。
- 数据描述规范:允许数据工作者通过对齐相应的列来收集数据集
- 微调插件:适配最先进高效微调方法的插件,使得训练器可通过替换默认方法来激活
-
LLaMA Factory基础配置信息
- GPU显存要求
- 最低配置:
8GB显存(支持对7B参数的轻量级模型进行微调) - 推荐配置:
24GB及以上显存(如NVIDIA A10、RTX 4090 Ti、NVIDIA A100等),可支持更大模型(如Llama3-8B)的微调 - 国产化:支持 昇腾 910B 系列 NPU(包括 32GB 和 64GB 显存版本),且验证过基于鲲鹏 920 CPU 和 EulerOS 操作系统的昇腾服务器环境
- 最低配置:
- 其他硬件环境
- 内存: 至少16GB的系统内存。对于大规模模型训练,则需要使用更多内存。
- 存储: 足够的硬盘空间来存储模型文件和数据集。建议至少100GB的可用空间
- 注意事项
- 多卡支持:若使用多卡微调,需配置分布式训练工具(如DeepSpeed),且显存总和需满足模型需求。
- 模型适配:不同模型(如7B、13B、70B)对显存的需求差异较大,需根据具体任务调整配置。
- 推理优化:若仅用于推理,显存需求可适当降低,但仍需满足模型加载的基本要求
- 其他软件配置
必需项 至少 推荐 可选项 至少 推荐 python 3.9 3.10 CUDA 11.6 12.2 torch 2.0.0 2.6.0 deepspeed 0.10.0 0.16.4 transformers 4.45.0 4.50.0 bitsandbytes 0.39.0 0.43.1 datasets 2.16.0 3.2.0 vllm 0.4.3 0.8.2 accelerate 0.34.0 1.2.1 flash-attn 2.5.6 2.7.2 peft 0.14.0 0.15.1 trl 0.8.6 0.9.6 - GPU显存要求
LlamaFactory 方案调研
- 阿里云单租户DSW实例
- 创建实例
- 实例规格选择:建议使用NVIDIA A10 GPU(显存24GB GDDR6,算力仅次于A100/H100等旗舰型号)或更高配置。
- 镜像选择:建议使用Python3.9及以上版本。本方案在官方镜像中选择modelscope:1.18.0-pytorch2.3.0-gpu-py310-cu121-ubuntu22.04。
- 选择交互式建模环境(类似DSW)
- 新建一个GPU实例(建议选择V100/A10等支持BF16计算的显卡),配置存储空间(需预留20GB+用于模型和数据)
- 启动Jupyter Notebook
- 实例创建完成后,点击打开进入开发环境
- 在Launcher中选择Python 3 Notebook作为开发工具。
- 创建实例
阿里云DSW 提供多种 预装主流框架的镜像(类似Docker容器模板)。
- 固定环境:创建DSW实例时,直接在控制台选择所需镜像(如PyTorch 2.0 + CUDA 11.8),系统会自动加载环境。
- 自定义环境:若官方镜像不满足需求,可通过以下方式 固化自定义环境:基于基础镜像启动临时DSW实例。在Notebook中安装额外依赖(如!pip install llamafactory)。将当前环境 保存为自定义镜像,后续创建实例时复用。
- 存储卷挂载:通过绑定 持久化存储卷(如阿里云NAS/OSS),可将环境配置(如conda虚拟环境、pip包)永久保存,即使释放实例后仍可快速恢复。
- 云厂商的集成llamafactory的方案
- 华为云
- 原理:在ModelArts中,用户可通过创建Notebook实例(配置为Ubuntu 20.04 + CUDA 11.7 + PyTorch 2.0.0),直接使用预装环境或自定义镜像启动LLaMA Factory。支持SSH远程连接和Web UI可视化操作,简化了微调配置。
- 注意点:昇腾910B芯片的架构还需要安装 Ascend CANN Toolkit 与 Kernels来完成,详细链接
- 腾讯云
- 原理:使用GPU云服务器(如ecs.gn7i-c8g1.2xlarge),选择预装PyTorch和CUDA的镜像,安装llamafactory后启动Web接口服务
- 阿里云:
- 原理:于PAI平台DSW实例(推荐A10 GPU + 24GB显存),使用官方镜像modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04
- 注意点:阿里云支持固定镜像和自定义镜像
- 天翼云:
- 原理:部署于GPU云主机,手动配置CUDA 11.8 + PyTorch 2.2.2环境。
- 注意点:启动Web服务:CUDA_VISIBLE_DEVICES=0 python src/webui.py ,需放行7860端口
- 火山云:
- 原理:使用预装LLaMA-Factory的GPU镜像(Ubuntu 20.04 + CUDA 11.7),创建实例后直接启动服务,开箱即用。
- 优化:支持实时监控训练状态与断点管理,适配大规模数据集
- 移动云:
- 原理:基于GPU实例手动部署,推荐配置CUDA 12.1 + PyTorch 2.4.0
- 注意点:配置安全组放行端口,支持SSH隧道访问
- 华为云
- LLM数据集及模型下载
- 国内下载
- 具备外网代理
- 直接连接:huggingface官网
LLaMA Board
概述
- LLama Factory 提供了一个直观的 Web UI,用户可以通过该界面方便地进行模型微调、参数调整及监控训练任务的进度。
- Web UI 主要分为四个界面:训练、评估与预测、对话、导出。
安装LLaMA-Factory
-
创建notebook
- 关联VPC网络:需要配置公网,才能拉取模型
- 存储卷:需要至少300G,才能跑起来7B以上的模型,以下为官方参考值
方法 精度 7B 14B 30B 70B x B Full (bf16 or fp16) 32 120GB 240GB 600GB 1200GB 18x GB Full (pure_bf16) 16 60GB 120GB 300GB 600GB 8x GB Freeze/LoRA/GaLore/APOLLO/BAdam 16 16GB 32GB 64GB 160GB 2x GB QLoRA 8 10GB 20GB 40GB 80GB x GB QLoRA 4 6GB 12GB 24GB 48GB x/2 GB QLoRA 2 4GB 8GB 16GB 24GB x/4 GB 
-
打开创建的notebook
-
顺序执行以下命令
- 注意不能使用最新版本,进行镜像环境的安装,如何需要使用最新版本建议直接使用官方镜像
mkdir -p /home/jovyan/extension && cd /home/jovyan/extension git clone -b v0.9.1 https://gitee.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install --upgrade pip pip install -e ".[torch,metrics,torch-npu,bitsandbytes,modelscope,deepspeed]" --no-build-isolation -
运行环境完整性测试文件
import torch import torchvision import transformers import gradio as gr import torch_npu import os import subprocess #import deepspeed print("gradio版本:",gr.__version__) print("Transformers版本:", transformers.__version__) # 同样使用双下划线 [[16]] print(f"PyTorch 版本: {torch.__version__}") print(f"Torchvision 版本: {torchvision.__version__}") #print(f"deepspeed 版本: {deepspeed.__version__}") print(f"检查NPU是否可用: {torch.npu.is_available()}, 数量:{torch.npu.device_count()}") print("显示矩阵即为PyTorch安装成功") a = torch.ones(3, 4).npu(); print(a + a); print("***********PyTorch安装成功********") print("对 LLaMA-Factory × 昇腾的安装进行校验:") command1 = "llamafactory-cli env" subprocess.run(command1, shell=True) print("***********LLaMA-Factory × 昇腾安装成功********") print("*********昇腾驱动安装成功,则回显以下信息********") subprocess.run("npu-smi info", shell=True) print("***********昇腾驱动安装成功********") print("昇腾CANN版本**********") command2 = "cat /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/ascend_toolkit_install.info" print("昇腾CANN版本安装成功**********") subprocess.run(command2, shell=True ) print("验证deepspeed是否安装成功") subprocess.run("ds_report", shell=True ) print("deepspeed安装成功**********") -
运行启动文件
- 创建
start_llamafactroy.py文件,并写入以下代码 - 启动脚本:
python start_llamafactroy.py
import os import subprocess from urllib.parse import urlparse import torch import torch_npu def build_gradio_root_path(): jupyter_url = os.getenv("JUPYTER_SERVER_URL", "") if not jupyter_url: return "" parsed = urlparse(jupyter_url) path = parsed.path.rstrip('/') return path def start_llamafactory_webui(): torch.npu.set_device(0) # 设置默认设备为 NPU? # 设置环境变量 env = os.environ.copy() env["ASCEND_DEVICE_ID"] = "0" #设置华为npu设备ID,否则微调出错? env["ASCEND_RT_VISIBLE_DEVICES"] = "0" env["GRADIO_SHARE"] = "False" env["GRADIO_SERVER_NAME"] = "0.0.0.0" env["GRADIO_SERVER_PORT"] = "7866" path = build_gradio_root_path() gradio_root_path = f"{path}/proxy/7866/" env["GRADIO_ROOT_PATH"] = gradio_root_path env["USE_MODELSCOPE_HUB"] = "True" # 输出链接 print(f"\n*Wait a moment, LLaMA Board will run on this port: https://<当前jupyerlab的IP:端口>{gradio_root_path}\n") # 执行命令 command = "llamafactory-cli webui" subprocess.run(command, shell=True, env=env) if __name__ == "__main__": start_llamafactory_webui() - 创建
使用LLaMA-Factory
- 启动脚本文件
- 命令:
python start_llamafactroy.py - 启动:
等待一会LLaMA Board在本地端口启动服务后(Running on local URL),点击上面链接,即可跳转到LLaMA Board页面
- 命令:
- LLaMA Board模型基本配置
- 模型名称:选择合适的模型进行拉取,注意
不同的模型对于Transformer版本或其他相关框架可能存在具体的版本依赖 - 数据路径:从根目录到
LLaMA-Factory/data的绝对路径,默认为/home/jovyan/extension/LLaMA-Factory/data - 数据集:如果填写正确的数据路径后,就可以在下拉框中选择合适的数据集对模型进行微调
- 计算类型:昇腾环境对于bf16支持可能存在问题,最好选用
fp16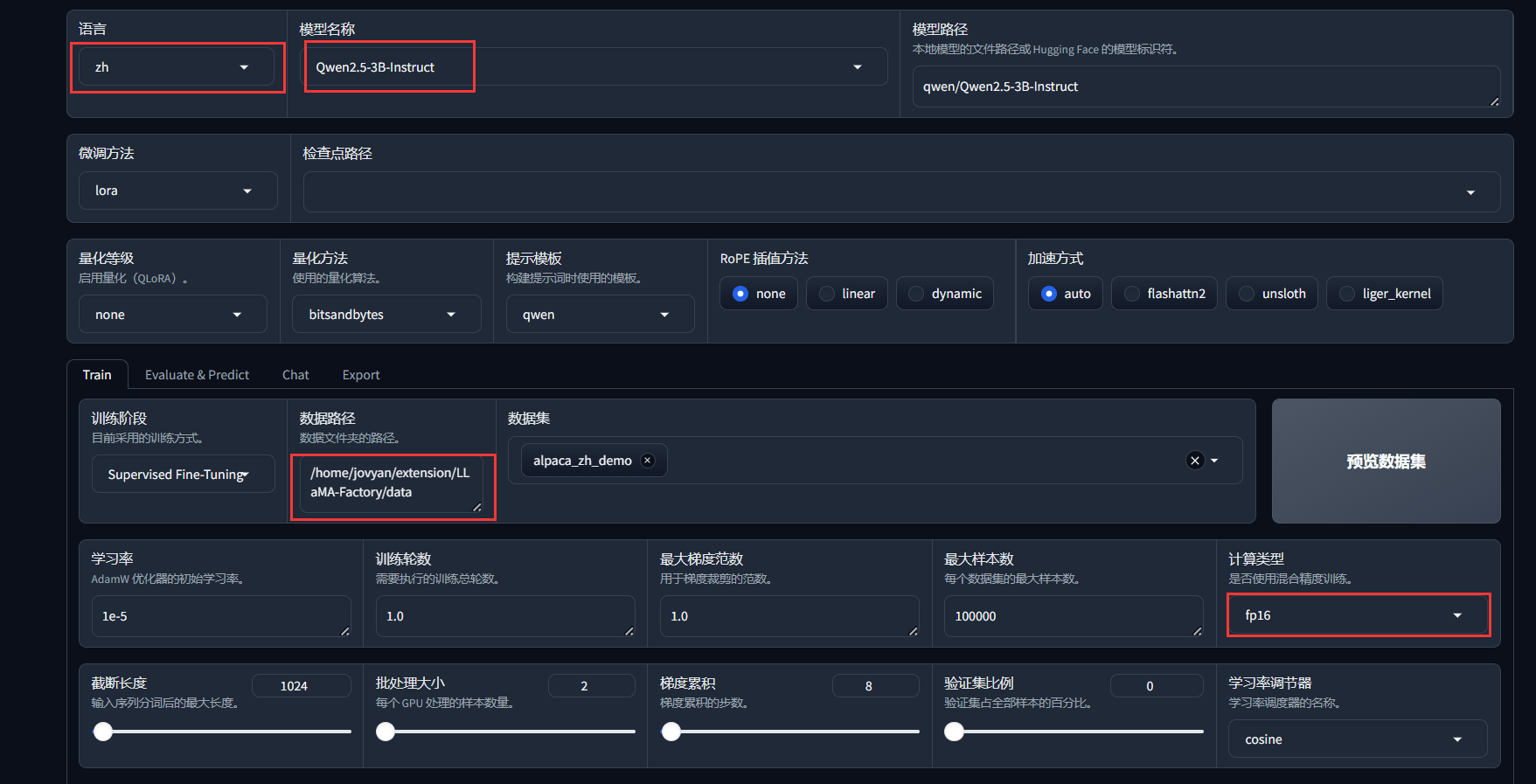
- 模型名称:选择合适的模型进行拉取,注意
- LLaMA Board模型其他配置
- LoRA+学习率比例:使用LLaMA-Factory时,指定loraplus_lr_ratio=16并挂载至所有线性层(lora_target=all),可显著提升拟合效果
- 保存路径:可以自定义输出的结果路径,后续使用
- 开始:点击后即可开始执行,最终将输出训练过程中的损失下降趋势图
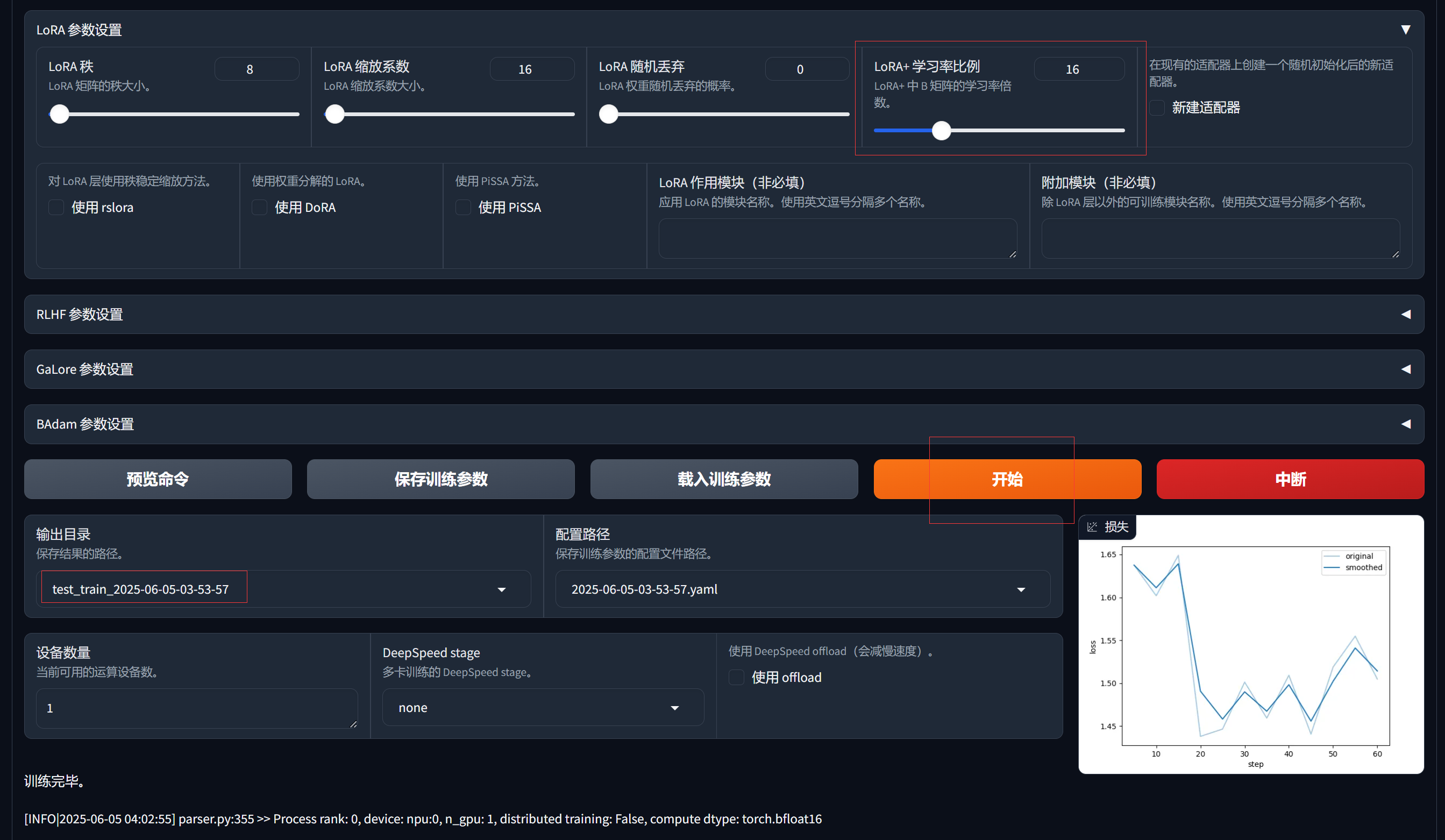
- 推理功能
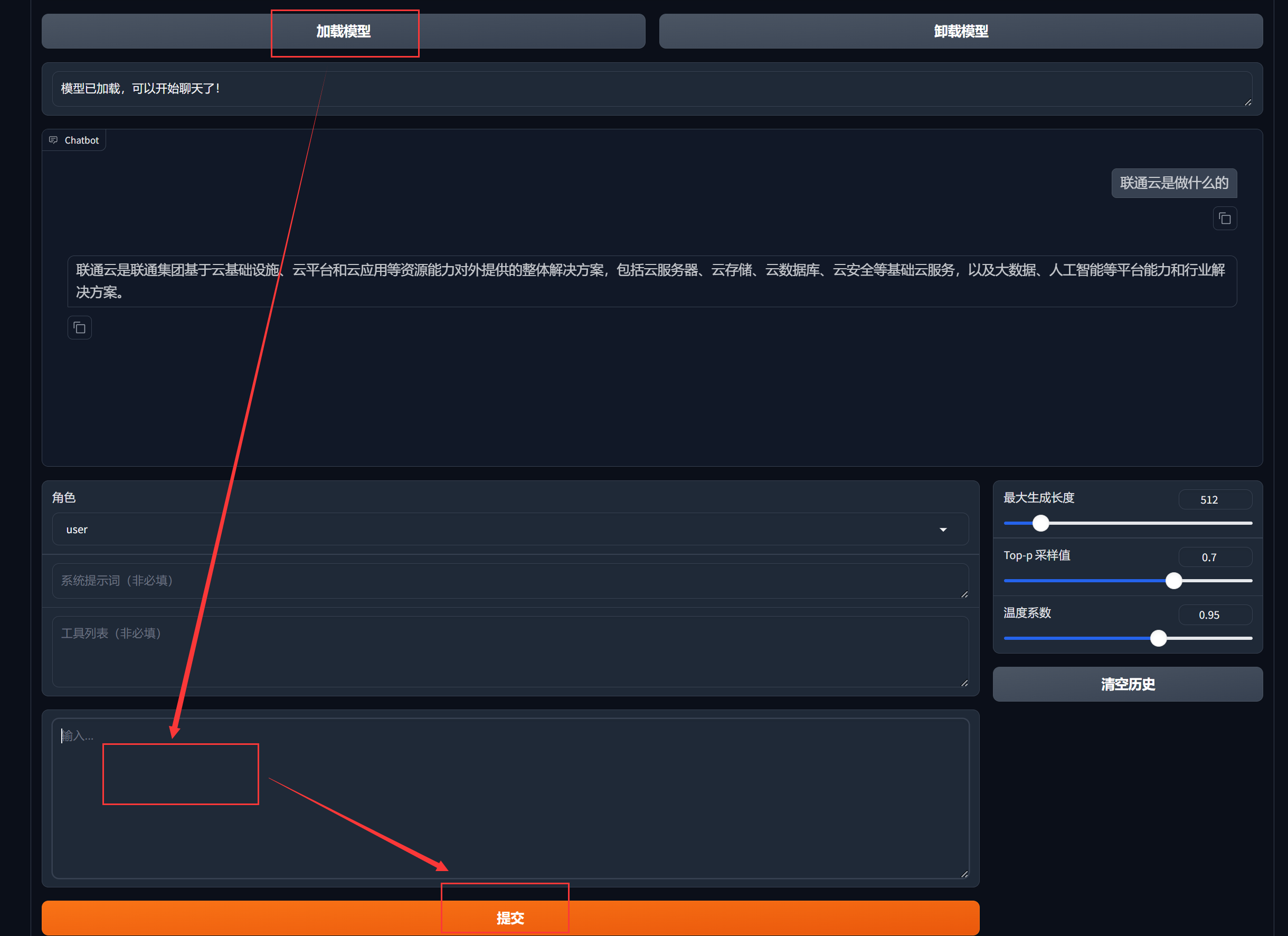
- 检查点路径:选择微调后的模型检查点(保存训练后的现场快照)
- 选择Chat功能后加载模型,即可进行对话
- 推理对话
- 输入:输入提示词
- 提交:点击后,模型将进行对话
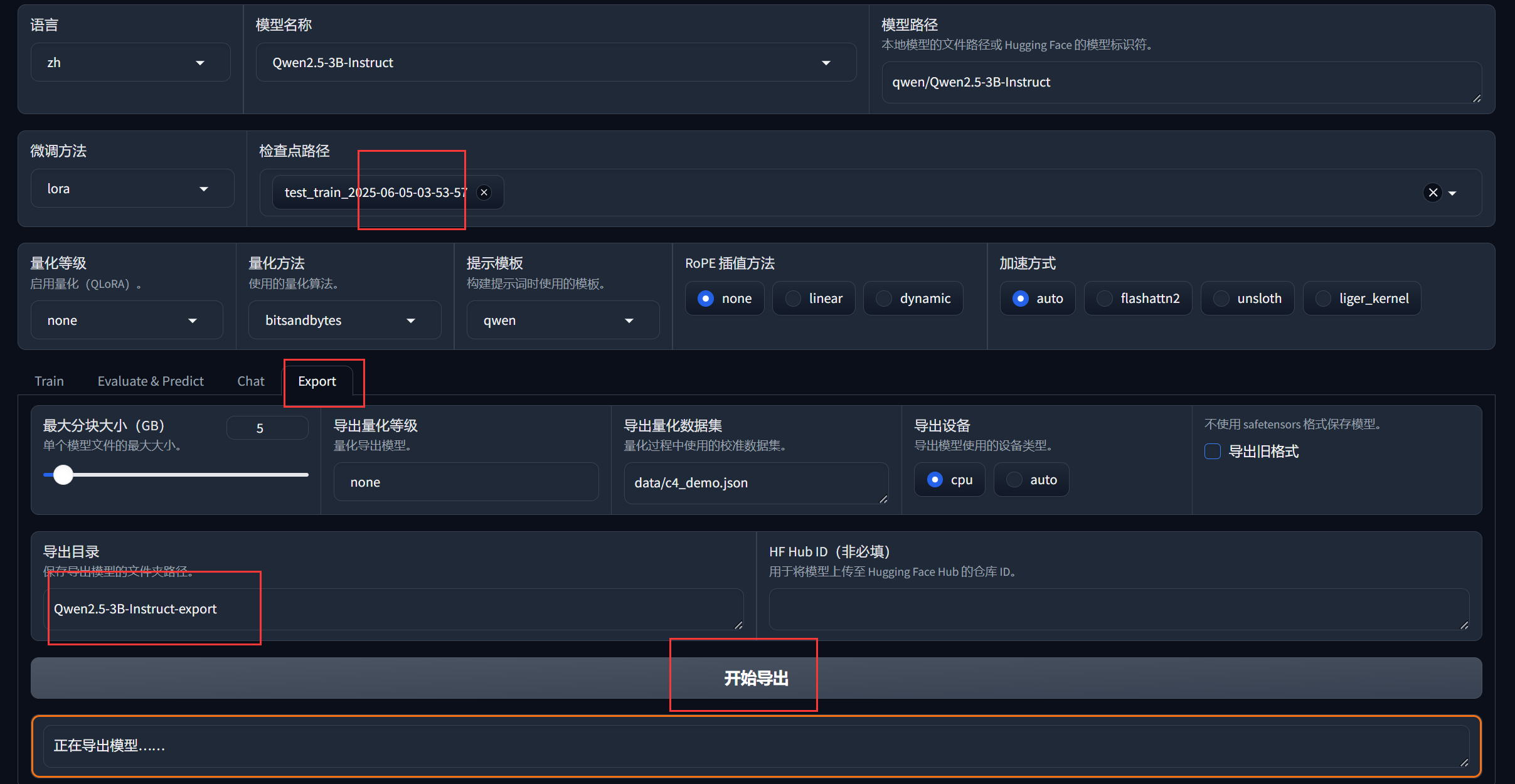
- 模型导出
- 卸载对话模型
- 选择检查点路径
- 自定义导出目录
- 开始导出

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)