MoE(Mixture of Experts)架构实战:稀疏激活大模型训练指南
尽管MoE在成本与性能平衡上取得突破,路由策略优化、训练稳定性、跨平台一致性仍是待攻克的核心难题。随着DeepSeek-V2、蚂蚁LingMoE、华为Pangu Ultra等模型的实践验证,中国团队在MoE领域已形成从框架(Megatron-Core)、算法(COMET)到硬件(昇腾)的完整技术栈。实战建议:初学者可从MiniCPM-MoE-8x2B等轻量模型入手,使用阿里开源的工具链快速启动训练
混合专家模型(Mixture of Experts,MoE)作为大模型稀疏化的核心技术,正以惊人的效率突破改写大模型训练的游戏规则。只需10万美元即可训练出匹敌Llama-2的模型,万卡集群训练成本直降40%,国产硬件上跑通准万亿参数模型——这些看似不可能的成就,皆因MoE架构的成熟而成为现实。本文将深入解析MoE核心原理,并手把手教你克服训练难点,实现高性能稀疏大模型训练。
一、MoE架构核心:用“稀疏激活”撬动千亿参数
MoE的核心思想是通过动态路由机制,让每个输入仅激活少量专家(Expert),实现参数规模与计算成本的解耦:
-
专家网络:通常由多个结构相同的前馈网络(FFN)组成,每个专家具备特定领域处理能力
-
路由网络(Router):轻量级神经网络,根据输入特征计算各专家的激活权重
-
稀疏激活机制:每层仅激活Top-k个专家(通常k=1或2),90%以上参数处于“休眠”状态
性能对比实例:
华为Pangu Ultra MoE(7180亿总参数,390亿激活参数)在昇腾集群上实现41% MFU(模型浮点利用率),推理吞吐达35K tokens/s,性能媲美同等激活规模的稠密模型,总参数量却扩大18倍。
二、架构设计实战:避开负载不均衡的深坑
1. 专家结构创新
-
细粒度专家+共享专家:蚂蚁LingMoE将专家切分为更小单元,同时引入跨任务共享专家,平衡专业化与通用性
-
幂次化专家规模:华为Pangu Ultra根据昇腾NPU特性,将专家维度设计为2^n,最大化硬件利用率
2. 路由算法优化
-
负载均衡损失函数:华为提出EP-Group辅助损失,在专家并行组粒度施加约束,既避免负载不均又不损害表达能力
-
Dropless路由:阿里Megatron-Core集成GroupedGEMM算子,支持变长输入处理,彻底告别Token丢弃
# 基于PyTorch的负载均衡损失实现
def load_balancing_loss(router_probs, expert_indices, num_experts):
# 计算每个expert处理的token比例
expert_mask = F.one_hot(expert_indices, num_classes=num_experts)
density = expert_mask.float().mean(dim=0)
# 计算router选择expert的强度
router_prob = torch.gather(router_probs, -1, expert_indices.unsqueeze(-1))
strength = (router_prob.squeeze() * expert_mask).sum(dim=0) / (density + 1e-6)
# 负载均衡损失
balance_loss = num_experts * (density * strength).sum()
return balance_loss三、训练效率优化:通信与计算的博弈艺术
1. 通信瓶颈破解方案
-
分层All-to-All通信:华为在昇腾集群上实现通信开销<2% 的关键:
-
节点内:利用高带宽NVLink进行Token冗余分发
-
节点间:执行去重Token收集,减少跨节点流量
-
-
算子级通信隐藏:字节COMET系统通过细粒度计算-通信折叠技术,将GEMM计算与NVSHMEM通信融合,端到端训练提速1.71倍
2. 内存优化技巧
-
Selective重计算+Swap:华为精准内存手术方案节省70%激活值内存,支持微批次规模翻倍
-
W4A4量化实战:采用FlatQuant算法平坦化激活分布,显存需求降至FP32的12.5%
四、低成本训练实战:消费级GPU上的MoE训练
1. 训练策略创新
-
两阶段训练法:JetMoE-8B使用1T token常量学习率预训练 + 2500B token衰减训练,仅用96张H100两周完成训练(成本8万美元)
-
异构硬件适配:蚂蚁LingMoE在国产GPU上实现3000亿参数训练,关键技术:
-
DLRover:动态负载调度框架
-
Babel跨集群同步:解决数据异构访问问题
-
2. 稳定性保障方案
| 问题类型 | 华为Pangu解决方案 | 效果提升 |
|---|---|---|
| 梯度突刺 | 深度缩放三明治归一化(DSSN) | 突刺比例↓50% |
| 硬件迁移差异 | TinyInit小初始化策略 | 跨平台Loss差异<0.1% |
| 专家负载不均衡 | EP-Group辅助损失 | 多任务性能↑1.5% |
五、强化学习后训练:解锁MoE全潜力
华为首次披露MoE+RLHF超节点训练关键技术:
-
RL Fusion训推共卡:支持DP/TP/EP/PP动态切换,资源利用率翻倍
-
StaleSync准异步机制:容忍梯度“陈旧性”,训练吞吐提升50%
-
DistQueue数据队列:解耦多任务数据依赖,减少阻塞等待
奖励模型设计技巧:
# 多能力项奖励系统示例
def multi_ability_reward(output, reference):
math_reward = math_grader.score(output, reference) # 数学能力评分器
code_reward = code_bleu(output, reference) # 代码BLEU评分
safety_reward = safety_checker(output) # 安全性评分
# 加权综合奖励
total_reward = 0.6*math_reward + 0.3*code_reward + 0.1*safety_reward
return total_reward六、国产化实践:从芯片到框架的全栈突破
-
昇腾硬件的适配秘籍:
-
算子调度优化:Host-Device协同下发,Host-Bound开销<2%
-
定制通信原语:适配华为CloudEngine交换机拓扑
-
-
Megatron-Core MoE生态:
-
支持专家并行(EP)+数据/张量/流水线并行3D融合
-
GroupedGEMM解决多专家变长输入问题
-
-
典型部署方案对比:
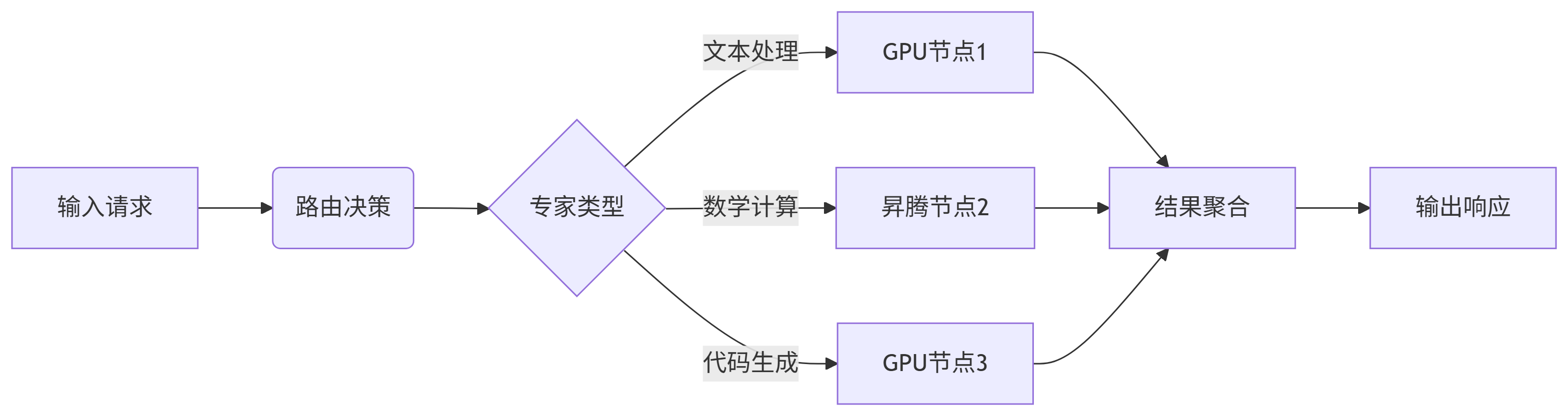
结语:MoE的未来与挑战
尽管MoE在成本与性能平衡上取得突破,路由策略优化、训练稳定性、跨平台一致性仍是待攻克的核心难题。随着DeepSeek-V2、蚂蚁LingMoE、华为Pangu Ultra等模型的实践验证,中国团队在MoE领域已形成从框架(Megatron-Core)、算法(COMET)到硬件(昇腾)的完整技术栈。
实战建议:初学者可从MiniCPM-MoE-8x2B等轻量模型入手,使用阿里开源的PAI-Megatron-Patch工具链快速启动训练,逐步掌握细粒度专家划分与动态路由调优技巧。
让天下没有难训的大模型——MoE正将这一愿景变为现实。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)