登录社区云,与社区用户共同成长
邀请您加入社区
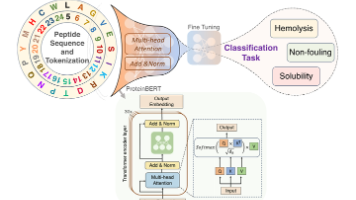
PeptideBERT(Peptide Bidirectional Encoder Representations from Transforme- rs)是一种基于transformer架构,专门用于预测肽的关键性质的蛋白质语言模型,如溶血性(hemolysis)、溶解性(solubility)和抗非特异性吸附性(non-fouling)。
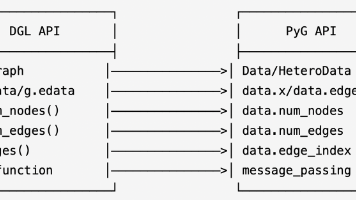
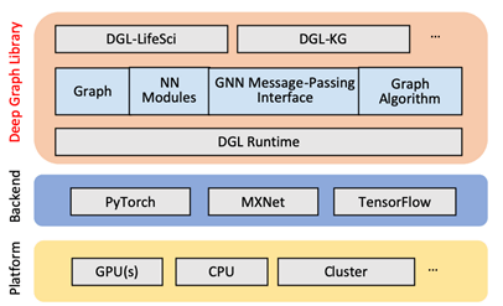
DGL (Deep Graph Learning) 和 PyG (Pytorch Geometric) 是两个主流的图神经网络库,它们在API设计和底层实现上有一定差异,在不同场景下,研究人员会使用不同的依赖库,昇腾NPU对PyG图机器学习库的支持亲和度更高,因此有些时候需要做DGL接口的PyG替换。SE3Transformer在RFdiffusion蛋白质设计模型中()作为核心组件,负责处理蛋白
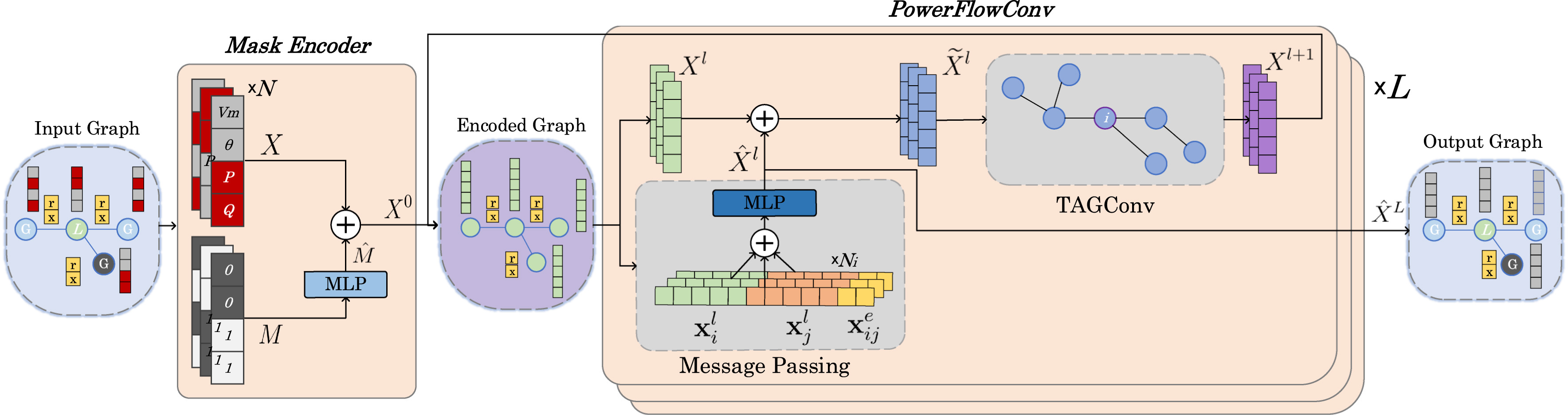
准确高效的潮流 (PF) 分析对于现代电网的运行和规划至关重要。因此,我们需要一种可扩展的算法,能够为小型和大型电网提供准确、快速的解决方案。由于电网可以理解为一张图,图神经网络 (GNN) 已成为一种颇具前景的方法,它通过利用底层图结构中的信息共享来提高 PF 近似的准确性和速度。
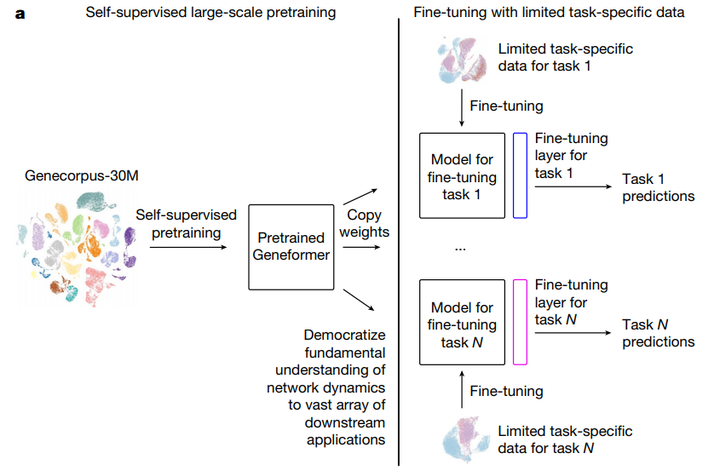
GeneFormer是一种基于 Transformer 架构的深度学习模型,专为基因表达数据分析而设计。它将基因视为“词汇”,将整个基因组的表达谱视为“句子”,通过自监督学习捕捉基因间的复杂调控关系和生物学背景,在医学研究中展现出强大的应用潜力。借助GeneFormer,研究人员能够更有效地处理和理解大量的基因组数据,从而加速新药开发、疾病治疗等领域的研究进展。在基因序列分析、蛋白质结构预测疾病机
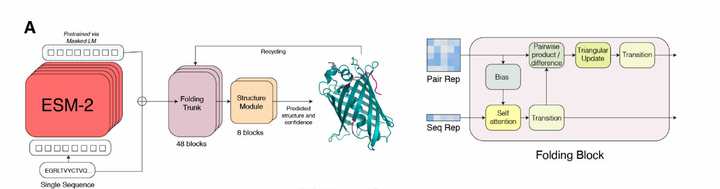
ESMFold是一种基于深度学习的蛋白质结构预测框架,其核心创新在于将超大规模蛋白质语言模型(如ESM-2)与几何优化模块结合,直接从氨基酸序列预测三维结构,于2023年正式发表于《Science》期刊。开源代码与预训练模型的发布,进一步降低了结构生物学的技术门槛,与AlphaFold2形成互补,共同拓展了计算驱动的蛋白质工程边界。ESMFold通过预训练的语言模型捕捉序列中的进化与结构关联性,结
6. 除了针对单一领域的模型与应用,通用模型是近年来的研究热潮。相比传统的深度学习任务,分子材料成像任务庞大繁杂,且数据结构、种类跨度极大,与AI的结合仍处于初期阶段,尚无业界认可的"包罗万象"的数据集,新提出的模型方法也没有公认的可以刷点对标的"benchmark",更没有 "大一统" 的AI模型,但考虑到分子材料成像领域的重要程度,或许在不久的将来,会有大量研究机构布局,科研人员扎堆,将“AI
G.ndata['y'] = th.randn(g.num_nodes(), 5) 不同名称的特征数据可以有不同形状。G.nodes[[0, 2]].data['x'] = th.ones((2, 5)) 对节点0,2设置特征数据。G.ndata['x'] = th.zeros((3, 5)) 对所有节点都设置特征数据,名称为x。G = dgl.graph((us, vs)) 一系列点和边,us-
PyG将每个图储存在一个Data中,但是消息传递是基于MessagePassing基类进行的,与Data或者Batch并无直接联系,通过在网络中重写message passing的forward,message,aggregate和update等方法实现自定义的消息传递过程,Propagete方法会自动调用这些方法完成数据的更新。根据Zhou Y等人做的实验来看,当节点和边的数量较小时,PyG的性
DGL昇腾安装时遇到的问题解决